
Voice cloning is a technology based on machine learning with the goal of seamlessly mimicking a person’s voice.
Voice cloning (VC) is an advanced technology powered by Artificial Intelligence (AI) that is capable of imitating a given person’s voice with uncanny precision. Neural Network architectures employed in the process can mimic subtle nuances, including intonations, regional accent, logopedic quirks, and even emotion.
Voice cloning is acknowledged as the most elusive and yet potentially devastating type of biometric fraud. Scam calls orchestrated with the help of VC are realistic, cheap to produce, and can be highly lucrative. According to the Federal Trade Commission, in 2022, VC-powered spoofing attacks resulted in $2.6 billion of losses. To tackle the dangers posed by this type of fraud, voice antispoofing methods have been deployed in corporate, financial, and other areas.

Voice Cloning Technology and Speech Processing Techniques
Typically, VC includes several stages:
- Sampling. Training material is gathered — samples of a target’s voice — that are “fed” into the Generative AI model.
- Analyzing. The voice characteristics are studied in a waveform and translated into mathematical values.
- Extracting features. Mathematical values that represent unique voice parameters are extracted and used as a training material.
- Synthesizing. At this stage, a cloned voice is generated by shaping a noise signal. This is, most probably, white noise, as it contains all spectrum frequencies audible to a human ear. (This is what gives it the name “broadband noise”.)
- Finalization. The mimicked voice can be either manipulated with a simple Text-to-Speech synthesizer to recite a given text, or used in a tandem with a voice conversion tool that disguises another person's voice with the cloned one in real time.
Usually, Generative Adversarial Networks (GANs) are used for this task, as they are equipped with a generator and discriminator duo: two components engaged in a “rival game” that allow the model to achieve the most believable results.
Some Voice Cloning Solutions
There is an assortment of VC tools that employ various methods:
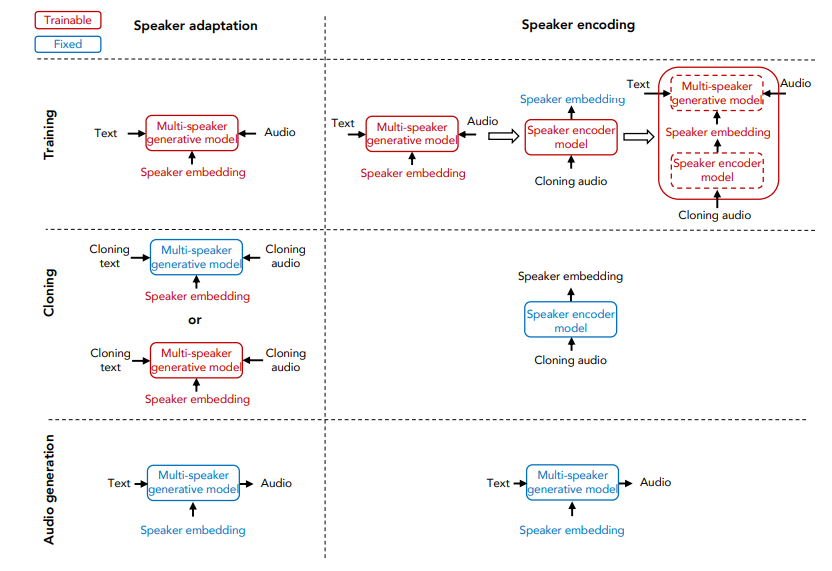
- Neural Voice Cloning with a Few Samples
Previously, it would have taken a large amount of samples to clone a voice. However, a newer approach featuring speaker encoding and adaptation allows for the same level of cloning with just a few training samples and far less computational resources.
- NAUTILUS
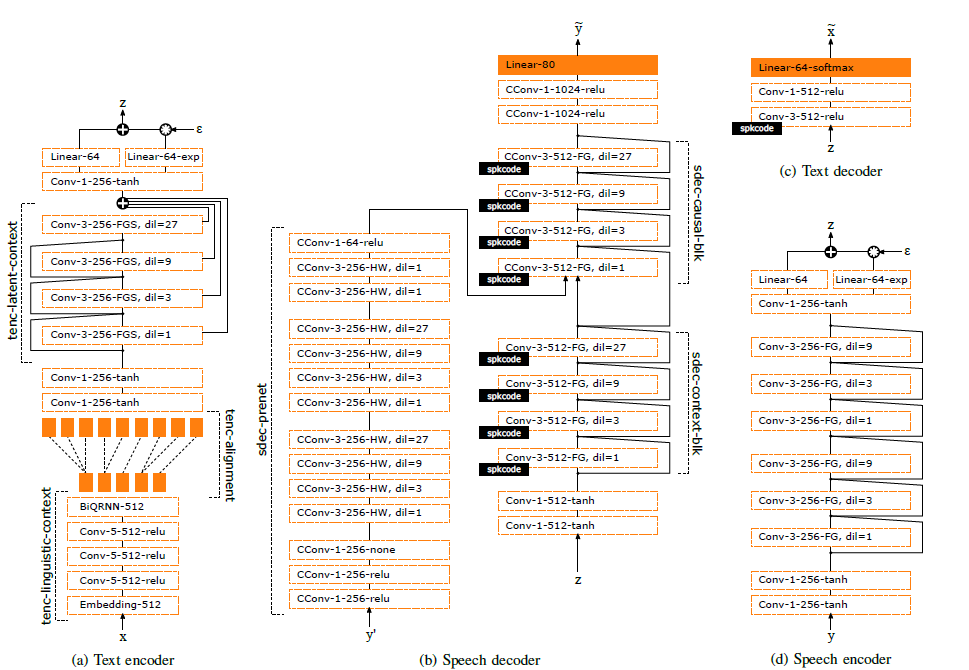
NAUTILUS is a one-shot model capable of cloning an “unseen voice,” meaning that it requires just a few seconds of untranscribed audio to imitate a voice. It relies on a multimodal architecture, which includes a backpropagation algorithm, latent linguistic embeddings, speech+text encoders and decoders, as well as a neural vocoder.
- Expressive Neural Voice Cloning
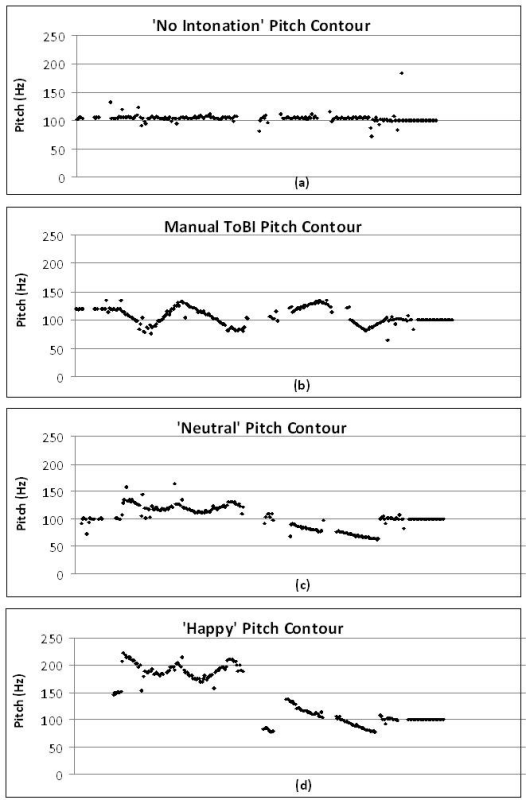
This solution suggests controllable voice cloning that preserves pitch and tempo of a speech, as well as its emotion. It relies on latent style tokens that retrieve independent prosodic styles from the training samples, pitch contour that tracks changes in the pitch and its impact over semantic meaning occuring in real time, speaker encoding, etc.
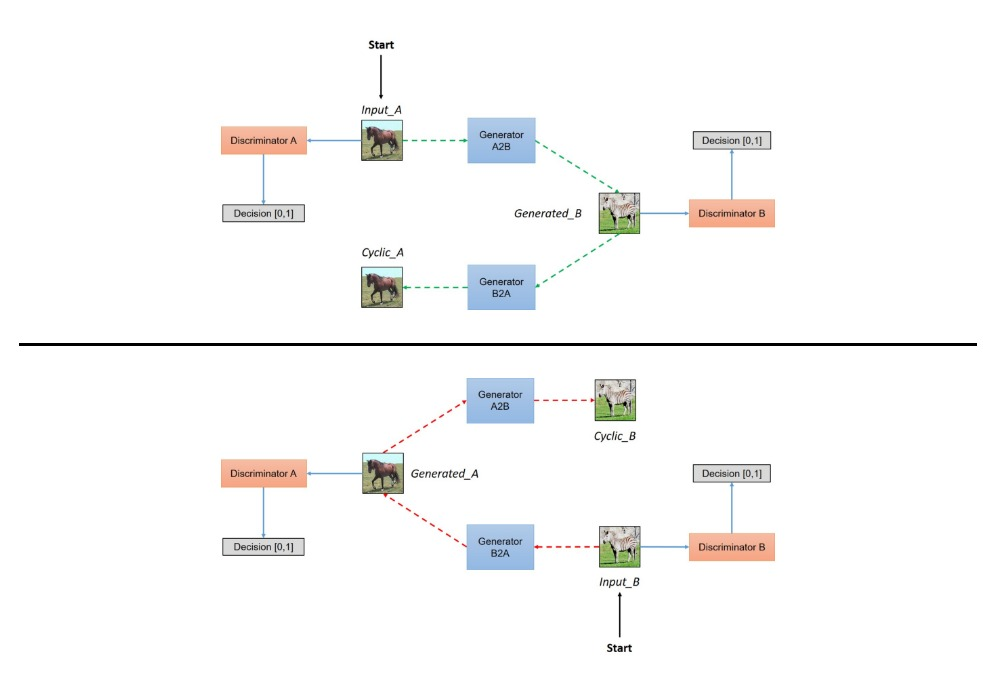
- Emotional Speech Cloning Using GANs
The mentioned approach combines a neural voice-synthesis tool with an EmoGAN — an adjusted version of CycleGAN that adds an emotional component to synthesized speech.
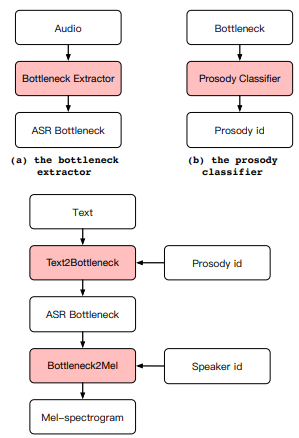
- Cloning Voice Using Very Limited Data in the Wild
The Hierotron-based model includes two components that perform independent functions: one is responsible for modeling the timbre, while the other adds the prosodic features – or, in other words, patterns of tone and emphasis.
- Diffusion Probabilistic Modeling
Diffusion probabilistic modeling requires merely 15 seconds of training audio and about 3 minutes of processing time to produce a cloned voice. It relies on a novel architecture with two encoders functioning on their input domain and a shared decoder trained in correspondence to the reverse diffusion.
- HiFi-GAN Model
The HiFi-GAN approach employs x-vector for target speaker’s characterization, competitive multiscale convolution to boost vocoder’s performance, and one-dimensional depth-wise separable convolution to push inference speed.
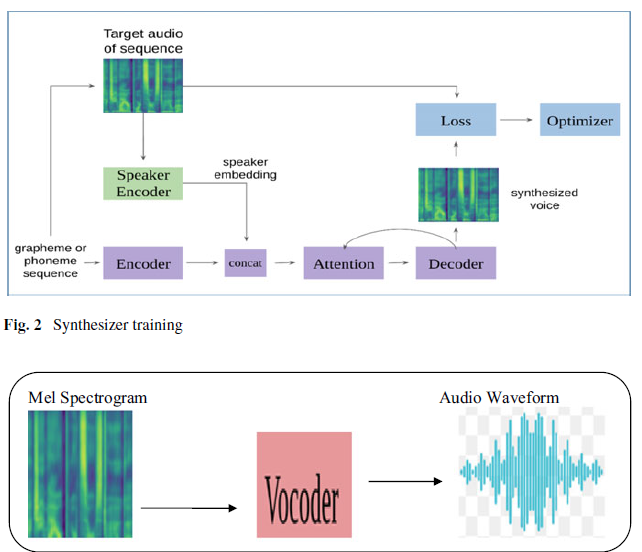
- Real-Time Voice Cloning System Using Machine Learning Algorithms
The proposed system combines a speaker encoder for embedding creation, synthesizer for generating Mel spectrograms transformed into sound, and a neural vocoder for audio wave conversion.
- Personalized Lightweight Text-to-Speech
In this case, a resource-efficient model is presented which relies on learnable structured pruning — it essentially produces a speaker’s model while requiring fewer resources. In turn, this makes it deployable on mobile gadgets.
- ZSE-VITS
ZSE-VITS is a zero-shot expressive version of VITS — a Conditional Variational Autoencoder – which also employs adversarial learning that provides end-to-end speech generation. It also utilizes TitaNet, which is a network capable of extracting speaker representations with the help of Squeeze-and-Excitation (SE) layers, 1D depth-wise separable convolutions, etc.
- A Real-Time Voice Cloning System with Multiple Algorithms for Speech Quality Improvement
AI-voice solutions often struggle at “reading” long text passages, polluting them with artifacts, mispronunciation, etc. A novel approach proposed in 2023 couples a text determination module to a synthesizer module, while also adding a noise reduction algorithm and a SV2TTS framework to achieve superior audio quality.
Potential Harm of Voice Cloning
It is hypothesized that VC will present a gamut of serious threats in the future, including disinformation campaigns, phone phishing, circumvention of voice recognition security systems, voicemail attacks, and so on.
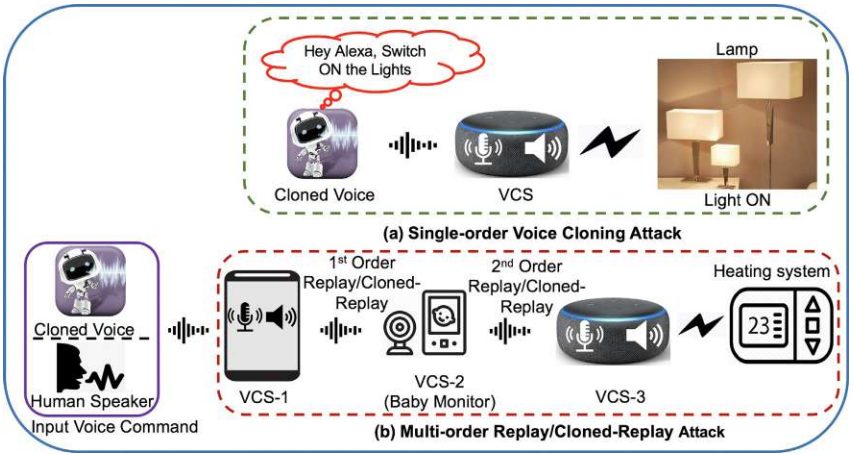
Cloned Voice Attack Models
There are several attack modalities exploiting an AI-mimicked voice:
- Interaction with a biometric security system. A cloned voice can be used to hack a banking app, secured terminal, digital account, remotely controlled device, and other avenues.
- Harming other individuals. This refers to hate speech, discrimination, disinformation, and other similar instances of negative interaction.
- Defamation. A cloned voice can be used to produce a false message on behalf of a specific individual or a company, institution, or even governmental entity.
The training samples for sculpting a synthetic voice can be obtained from a plethora of sources: voice notes from a messaging app, secretly recorded phone calls or live conversations, publicly available videos, mobile provider databases, etc.
Countermeasures against Cloned Voice Attack
Detecting VC attacks can be done either manually or by using sophisticated algorithms.
Manual Recognition of Cloned Voice Attacks
A cloned voice can be detected “manually” — without using special solutions — by a few red flags:
- No breath is heard during the speech.
- Strange artifacts, distortion, and noises.
- Shallow background knowledge related to a targeted person.
- A highly targeted topic related to sensitive personal details or finances.
- Misplaced syllable accent, lack of acceleration and deceleration in speech patterns natural to how humans talk (also known as “unnatural prosody”).
However, if fraudsters go through meticulous preparations, these hallmarks may become less and less noticeable as their technique is honed.
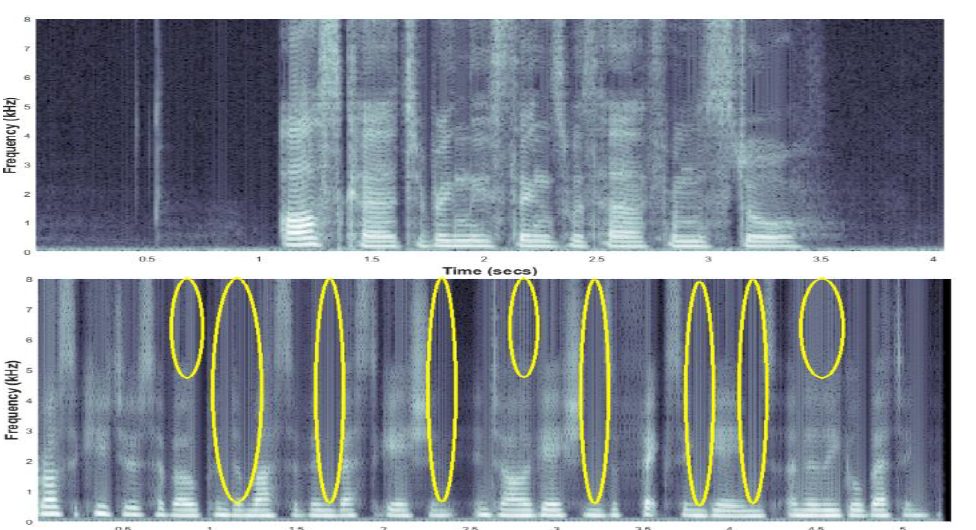
Cloned-Voice Detection Using Higher-Order Spectral Analysis
It is reported that synthesized speech can be spotted via detecting specific artifacts that are hidden from human perception. These artifacts emerge in every cloned voice, no matter which cloning algorithm was used.
- BiLSTM model
Bidirectional Long-Short Term Memory Machine (BiLSTM) is an antispoofing approach that features MFCC, GTCC, Spectral Flux, and Spectral Centroid. Together, they form a feature vector responsible for audio signal representation. This helps detect natural speech variation and tell it apart from synthetic artifacts, thus unmasking a spoofed voice.
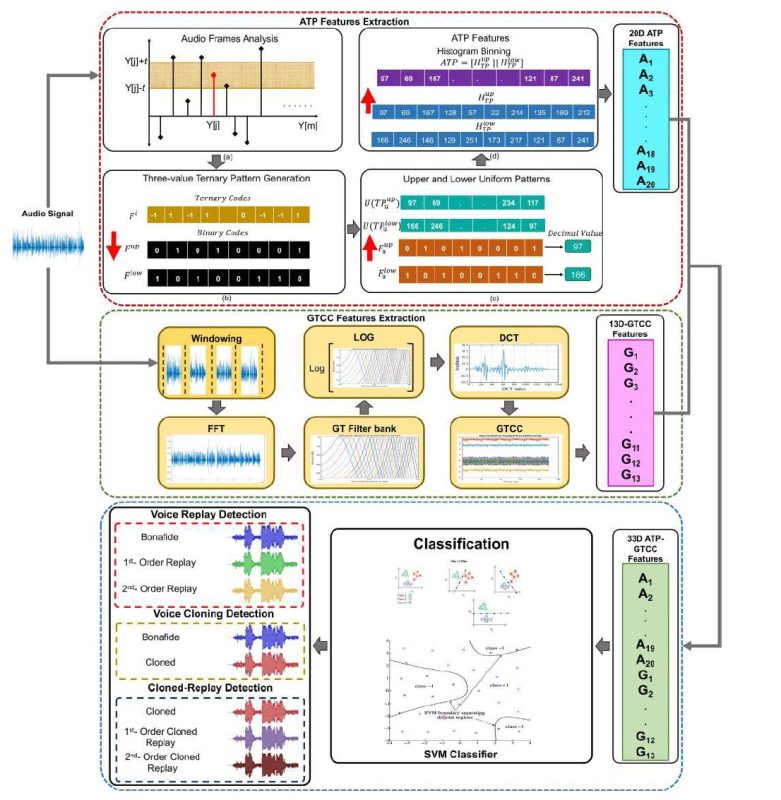
- Using Acoustic Ternary Patterns with Gammatone Cepstral Coefficients Features
Acoustic Ternary Patterns (ATP) and Gammatone Cepstral Coefficients (GTCC) help detect unnatural speech cadence, absence of pauses, wrong syllable accent, mispronounced words, and other signs of poor prosody inherent to synthesized voice.
- Single and Multi-Speaker Cloned Voice Detection
This approach suggests using three methods: low-dimensional perceptual features, generic spectral features, and well as end-to-end learned features. These allow for detecting a real human voice by its higher amplitude variability in speech.
- CloneAI
CloneAI is a Convolutional Neural Network (CNN) supported by Linear Frequency Cepstral Coefficients and Mel spectrogram that synergistically allows for analyzing speech features and filtering out voices that have subtle unnatural characteristics.
Cloned Voice Detection Experiments and Contests
A number of tests have been orchestrated to see how security models can prevent voice spoofing.
Evaluating Cloned Voice Detection Techniques
In one 2020 experiment, a duo made up of WaveNet and Tacotron Text-to-Speech synthesizer was tested against CNN-powered Automatic Speech Verification, and some other tools. The results showed that antispoofing solutions based on CNN, Gaussian Mixture Model - Universal Background Model, and others can actually show a decrease in their reliability when facing realistic voice cloning.
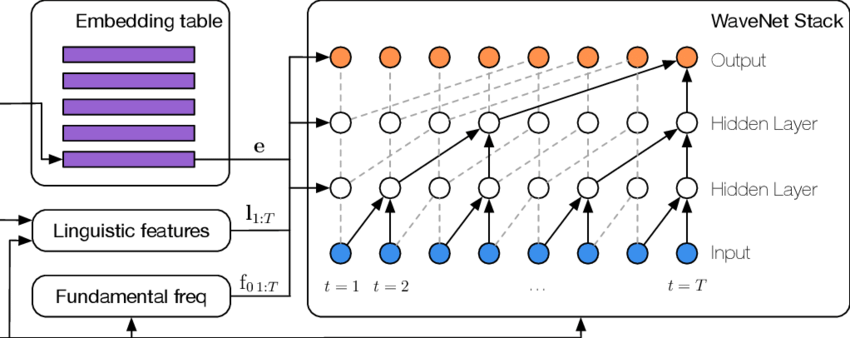
Multi-Speaker Multi-Style Voice Cloning Challenge
The M2VoC challenge was hosted in 2021. It featured two competition tracks divided into subtracks where Speech Quality, Speaker Similarity, and Style Similarity were assessed. Mean opinion score (MOS) was used to rate solutions. The results showed that LPCNet — a speech synthesizer based on WaveRNN — is quite efficient as it allowed the top teams to get the highest scores.
Comparison of the Neural Network Model and Human Performance
During the experiment, it was discovered that human listeners have a hard time distinguishing cloned and real voices with a 50% accuracy, which is basically a random chance. In the meantime, antispoofing solutions — such as Baidu’s Deep Speaker based on convolutional layers and ResNet-type blocks — showed a 98.8% immunity to VC attacks.
A number of contests have been devised to test the accuracy of voice liveness antispoofing tools. To learn more about these competitions and their detection methods, read on here.
 Antispoofing
Antispoofing




{kind=link}
{kind=link}