
Voice Liveness Detection: Definition, Goals & Methods
Voice liveness detection is a group of security measures, which detect and prevent voice spoofing attacks. These attacks can be characterized as a type of voice phishing. Although scams involving remote verbal communication existed since the earliest days of telephony, voice spoofing is a relatively novel threat.
With the rise of smart devices, the threats posed by fraudsters using voice phishing have intensified. Voice assistants such as Google Assistant, Siri, and Alexa are already widespread, with almost half of the US population reporting that they use it on a regular basis. However, while voice assistants use voice recognition to determine what a user is saying (e.g. to transcribe text or perform a task), voice authentication is used as a biometric security measure to confirm who is saying it. This may involve analyzing an individual’s unique voice patterns against a template, or even requiring the user to say a specific passphrase.
Voice is one of the most-used modalities for user authentication along with fingerprint, face, and iris identification – often used as part of multi-factor identification. It is a commonly used security layer in industries such as banking, where the system uses the speaker’s unique voice characteristics to determine whether a caller is the account holder. A report by Opus Research suggests that the number of users employing voice authentication in the banking sector will be upwards of 1.9 billion going into 2024 – up from 69 million in 2019.
Perplexingly, the emergence of deepfakes in 2017 showed that a human voice, just like a face, could be replicated realistically with the help of artificial intelligence (AI). This revolutionary technology galvanized experts to develop voice antispoofing techniques to ensure replicated voices cannot get past a voice authentication check.

Currently, there are numerous AI-powered tools capable of making lifelike voice replicas: SteosVoice (formerly CyberVoice), RealTalk, Resemble, and many others. They can imitate intonations, accents, vocal timbre and pitch, articulation, and other unique traits native to the human speech apparatus. Broad usage of voice authentication in mobile banking, e-commerce, virtual assistants, online healthcare (Amazon Transcribe Medical), and other spheres further proves how dangerous voice spoofing attacks can be. One such attack carried out in 2020 caused a UAE based company to lose $35 million to fraudsters.
Voice Liveness in Commercial Products
A number of online applications— mobile banking or booking services — employ voice recognition and verification. They are employed to improve customer experience and reduce the usage of PIN-codes, passwords or challenge questions. To ensure the security of voice recognition applications, a number of voice anti-spoofing solutions are proposed.
IDLive Voice
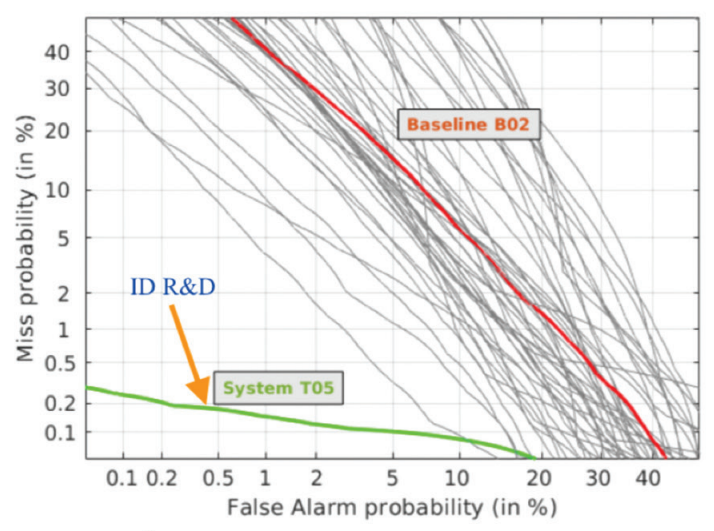
IDLive Voice developed by ID R&D is capable of identifying a synthesized voice "within milliseconds". As reported, ID Live Voice includes algorithms that can detect specific spectral artifacts inaudible to a human ear. Usually, such artifacts are left by speech conversion and usage of a Text-to-Speech generator. A similar approach suggests that short-term spectral features can be computed with the inverted frequency warping scale, as well as overlapped block transformation of filter bank log energies, which together allow detecting discrepancies between live and synthetic voices. Such a system can. among all else, successfully shield Automatic Speaker Verification systems.
Nuance
VocalPassword by Nuance is a tool that can detect pre-recorded and/or edited voice (cheapfake), which can be used for a spoof attack. Its mechanism is based on intra-session voice variation principle:
- A speaker makes an utterance to get verified.
- The system captures an audio sample from the utterance.
- Then the speaker is prompted to repeat a random part of their phrase.
- The system compares the received samples, drawing a liveness detection score.
VocalPassword employs VocalPassword’s Utterance Validation engine for automatic speech recognition. Additionally, it is enhanced with ‘fraudster detection’ — a feature, which registers and detects known fraudsters alerting the system about their presence.
VoiceVault
VoiceVault has developed a system against suspicious and fraudulent calls, especially aimed at seniors and individuals who "live far from financial institutions". (According to the FBI, the elderly citizens lost $1 billion to swindlers in 2020 alone.) The solution includes a biometric engine, which is capable of: a) Fending off replay attacks featuring prerecorded voices and b) Detecting liveness of the caller’s voice.
General solutions
Void system can be highlighted among generally applicable solutions.
Void
Developed by the South Korean researchers, Void is a detector/analyzer, capable of preventing replay attacks. The idea is based on signal power distribution analysis over the audible frequency range. Peak pattern identification in low- and high-power frequency ranges helps further evaluate the incoming signal.
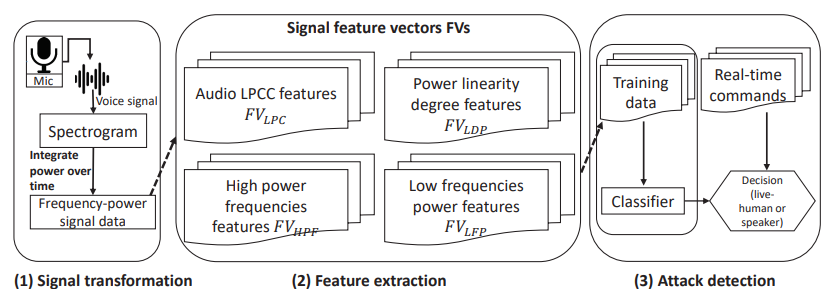
Void’s algorithm includes three steps:
- Signal transformation.
- Feature extraction.
- Attack detection performed in real time.
Furthermore, Void computes the following feature types in succession: Low frequencies power features (FVLFP), Signal power linearity degree features (FVLDF), Higher power frequencies features (FVHPF), LPCC features for audio signals (FVLPC).
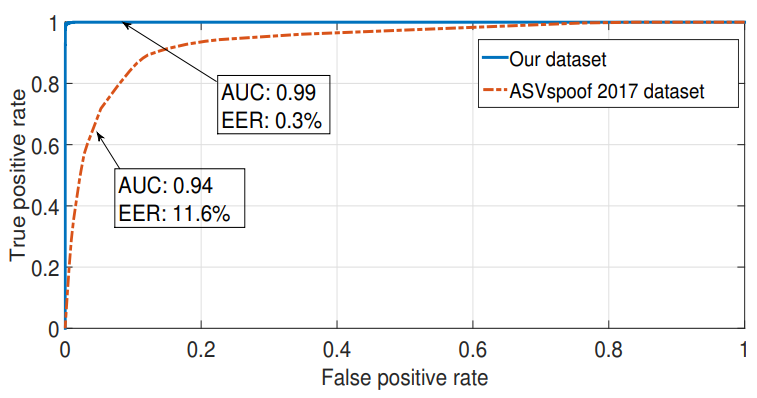
Void was tested on two datasets — private and public — and showed a 0.3% and 11.6% Equal Error Rate (EER), respectively. Furthermore, if enhanced with a Gaussian Mixture Model that employs Mel-frequency cepstral coefficients (MFCC), Void demonstrates an EER of 8.7% on a public dataset, while being more resource-efficient than a rival system based on deep-learning.
Voice Liveness Systems in Smartphones
For voice liveness detection in smartphones, the following solutions are proposed:
VoiceGesture
VoiceGesture is based on the idea of analyzing articulatory gestures produced by the phoneme sounds of a person. To detect liveness more accurately, a smartphone speaker is triggered during authorization. It will emit a 20kHz tone inaudible or barely hearable to a human ear. The in-built microphone will record both the passphrase and reflections of the tone, after which Doppler shifts in the same 20kHz region will be extracted. The audio data received will be then compared to a user’s audio profile created during the enrollment stage. If the similarity score is bigger than the threshold set by the profile, liveness will be confirmed.
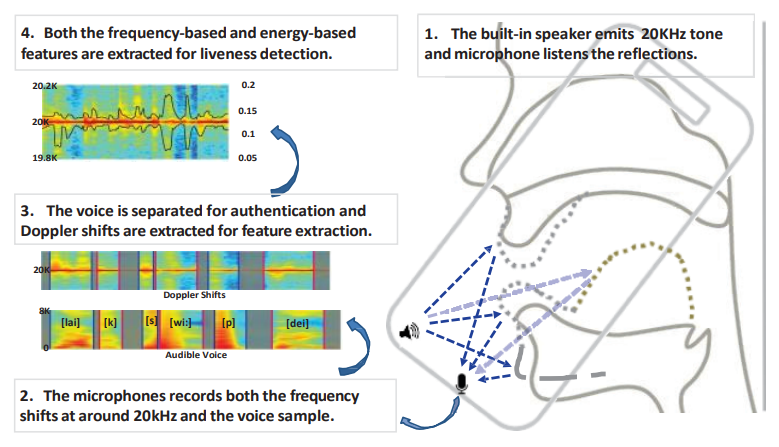
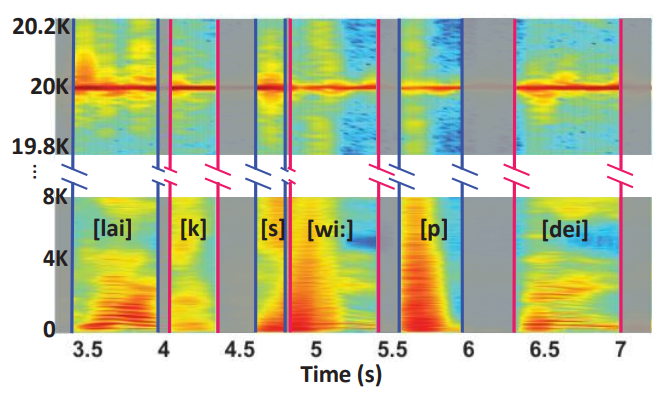
VoiceLive
VoiceLive is a similar method, which analyzes phonemes uttered by a user. Its core idea is to extract the time-difference-of-arrival (TDoA) dynamic of the input phrase and compare it to a passphrase already stored in the memory of the gadget. If the similarity score is higher than the preset threshold, authorization will be successful.
Voice Liveness in Voice Assistants
A few novel approaches have been developed for the Voice Assistants (VAs) as well.
LiveEar
LiveEar is based on the notion that human and synthetic speech have contrasting TDoA values, since phoneme positions in the vocal apparatus are always different. To do the analysis and validation, a model pre-trained with a large quantity of TDoAs is used. It employs techniques like phoneme segmentation, and phase-transform weighted generalized cross-correlation method (GCC-PHAT) for TDoA calculation, etc.
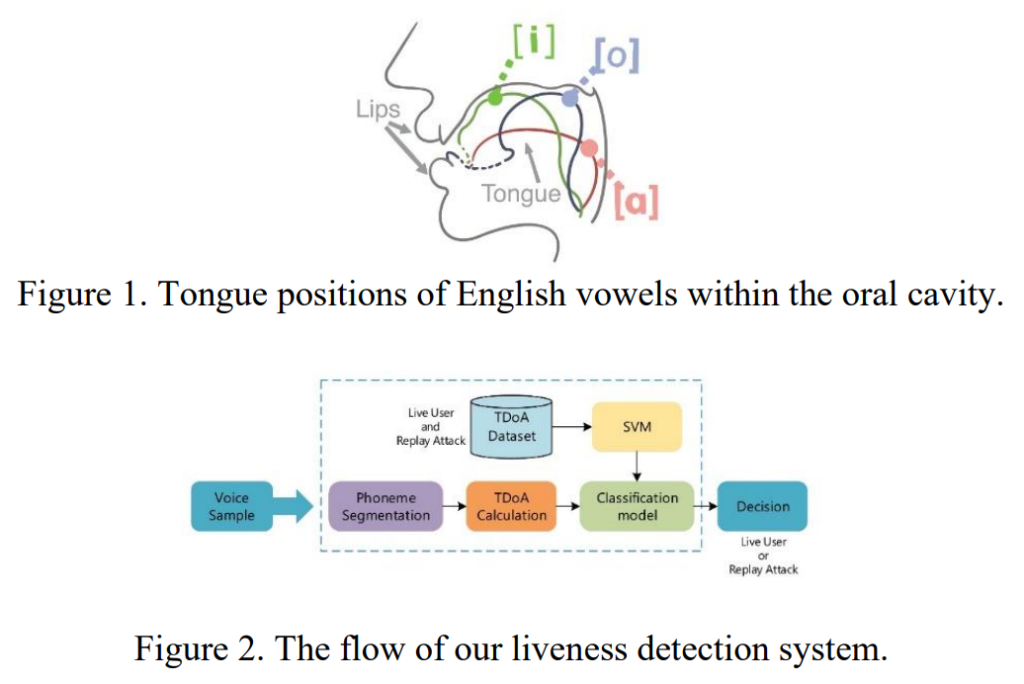
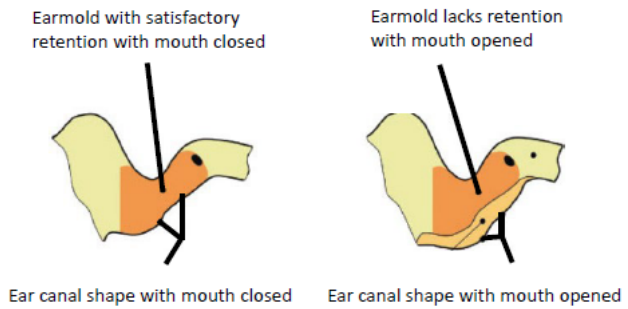
Detection Using Ear Canal Pressure
A study from Montclair State University suggests that liveness of a speaker can be detected by measuring air pressure in the ear canal with a sampling rate of 500 Hz. User’s voice should be recorded simultaneously with it. The method includes steps like signal segmentation based on Hidden Markov Model, resampling achieved with finite impulse response (FIR) and normalization, etc.

Voice Liveness Systems in Voice User Interface in Internet of Things (IoT)
As many modern IoT devices (and vehicles) can interact through voice user interface (VUI), they also require voice liveness detection as an essential component.
VibLive
VibLive explores a laryngeal formant, bone-conducted vibrations and other essential characteristics of a genuine human voice. These features are unobserved in the hi-end audio equipment used in replay attacks. In these attacks, the sound is produced by a diaphragm attached to a voice coil — it generates mechanically stable audio frequencies, which a human voice would not be capable of.
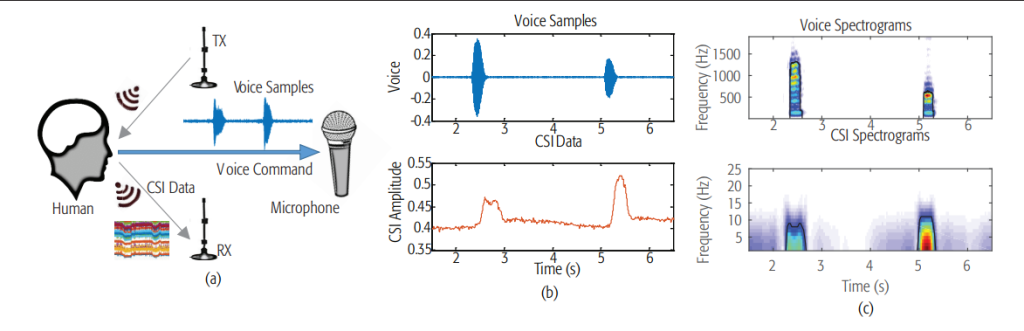
WiVo
WiVo is a two-factor authentication solution, which analyzes and links mouth motion to the phrases uttered by the speaker. It is done with the help of a channel-state information (CSI) approach that requires no additional gadgets. WiVo will use a pair of antennas of an IoT gadget to gather the CSI signals, while also recording speech of the accessor. It includes 4 steps: 1) CSI collection and voice recording, 2) Data preprocessing, 3) Feature selection, and 4) Detection. Similar to other methods, liveness will be validated if the pre-defined score threshold is exceeded.
FAQ
Voice liveness definition
Voice liveness is a set of characteristics intrinsic to a real human voice.
Voice liveness is one of the leading modalities in today’s biometric systems. In essence, it’s a group of features — or liveness cues — that indicate that the voice belongs to a living person. In turn these features help to formulate a biometric template. These features include articulatory gestures, vocal pitch and depth subtle inconsistencies, bone-conducted vibrations, and so on.
Apart from physiological nuances, individual behavioral traits are also checked by a liveness detection system. It can analyze vocal energy and volume, lexical preferences, unique logopaedical distinctions innate to every individual, and so forth.
Is voice liveness detection used in modern smartphones?
At least two voice anti-spoofing solutions are implemented in mobile technology.
As of now, two notable voice spoofing solutions are proposed for smartphone integration.
VoiceGesture is a solution, which focuses on articulatory gesture analysis. In other words, it examines phoneme sounds produced by a speaker. The system emits an inaudible 20kHz tone, while also recording speaker’s passphrase and tone reflections. Then, acoustic data is extracted from the recording to execute biometric matching.
VoiceLive performs time-difference-of-arrival (TDoA) dynamic extraction from a sample of the speaker’s voice. Then it calculates the similarity score to match it to the biometric template.
Where is voice liveness detection used?
Voice liveness detection is utilized in virtually all systems based on voice interaction.
Voice liveness is an integral security component utilized in many systems. Among them, we can highlight Automatic Speaker Verification (ASV), voice recognition in smart gadgets, Internet of Things (IoT), and voice assistants.
Another significant area of application is secure telephony. Voice deepfakes are known as the most popular AI-based attack instrument due to highly accurate voice cloning and accessibility. Therefore, it’s of utmost importance to prevent deepfake phone scams including those that target senior citizens. Fact-checking is another area, which also relies on anti-spoofing today.
What is voice recognition?
Voice recognition analyzes voice data as part of the biometric antispoofing.
Voice recognition is the ability of a system to receive and interpret a user's spoken commands. It is frequently used in applications such as google assistant and Alexa and is vulnerable to voice spoofing attacks. It is relatively easy to get a voice recording from a target or train a neural network to imitate their voice realistically.
Voice antispoofing is essential to voice recognition systems. It employs several techniques that can prevent potential attacks. They include audiovisual recognition, lip movement tracking, POCO-method with noise analysis, etc. These methods aim to differentiate high-quality fake voice samples or impersonations from a real person’s voice. Some voice antispoofing techniques can even detect a presentation attack, when a victim's voice sample is replayed with some high-definition acoustic equipment.
References
- Witcher 3 fan mode ‘A Night to Remember’ used CyberVoice to clone protagonist’s voice acting
- Human speech apparatus
- Amazon Transcribe Medical
- Fraudsters Cloned Company Director’s Voice In $35 Million Bank Heist, Police Find
- SteosVoice can synthesize realistic voices and currently is free of charge
- Spectral Features for Synthetic Speech Detection
- IDVoice™ Verified: AI-driven Voice Verification and Voice Anti-Spoofing
- VocalPassword™: voice biometrics authentication
- Senior citizens lost almost $1 billion in scams last year: FBI
- Void: A fast and light voice liveness detection system
- A Continuous Liveness Detection for Voice Authentication on Smart Devices
- VoiceLive: A Phoneme Localization based Liveness Detection for Voice Authentication on Smartphones
- LiveEar: An Efficient and Easy-to-use Liveness Detection System for Voice Assistants
- Voice Liveness Detection for Voice Assistants using Ear Canal Pressure
- Hidden Markov Model
- Air-conducted voice formation
- WiVo’s architecture
 Antispoofing
Antispoofing



{kind=link}