
Definition and Problem Overview
“Fake audio”, in most cases, refers to falsified audio data that impersonates the voice of a legitimate speaker. Although it may not be produced for ill-intentioned purposes, synthetic audio files made with voice-cloning tools are often used for committing fraud and spreading misinformation.

A rudimentary voice-imitating technology appeared in 1800 when inventor Wolfgang von Kempelen introduced his “speaking machine” — a contraption that consisted of bellows, windchest, mouth funnel, and other parts. The machine simulated human vocal tract and could be played like a musical instrument producing complete sentences in several languages.
In 1976, the first text-to-speech (TTS) technology — Kurzweil Reading Machine — was unveiled. The machine was the first to convert randomized text to speech, and was intended to help the blind and visually impaired.
While text-to-speech (TTS) technology was well underway, the replication of a realistic-sounding human voice was still facing barriers. The first TTS neural network, Google WaveNet was designed in 2006, which focused on intonation and inflection to attempt to make the generated speech sound more human.
Another early attempt of realistic voice imitation was produced by the company CereProc in 2008, who cloned George Bush's voice for entertainment and also restored the voice of Roger Ebert when he lost vocal function due to disease.

With the advent of machine learning — namely, Generative Adversarial Networks debuting in 2014 — voice-cloning became next-level. The new architecture made it possible to reproduce a person's voice, picking up highly unique and subtle prosody features: intonations, speech rhythm, and so on.
Voice deepfakes, due to their disturbing level of realism, are considered a vital threat to both Automatic Speaker Verification (ASV) systems and human individuals. In 2020, a voice spoofing attack enabled culprits to successfully pull off a $35 million heist of a UAE-based company. Events like these spurred the origin of voice antispoofing methods, with its various types and preventive techniques.

Theoretical Basis
Human vocalization is a complex process that is defined by numerous components: respiration, articulation, phonation, and so forth. Speech is produced by movement from different structures in the vocal tract — tongue, lips, vocal folds — while a stream of air is pushed up from the lungs through the larynx where arytenoid cartilages are activated.

Therefore, understanding how the human vocal tract and its physiological limitations work, as well as learning how it creates phonemes, is essential in synthetically reproducing a genuine human voice. Moreover, if researchers can understand what makes human voices unique, they can then develop approaches to differentiate fake and real voice samples.
The prevailing method used to distinguish false and genuine audio is based on a technique used in paleoacoustics — a scientific field that studies vocalization of the paleofauna based on the fossilized vocal organs. By analyzing their anatomy, paleontologists are capable of reconstructing approximate sounds that ancient animals produced: recreated examples include the Dryptosaurus and Utahraptor, among others.
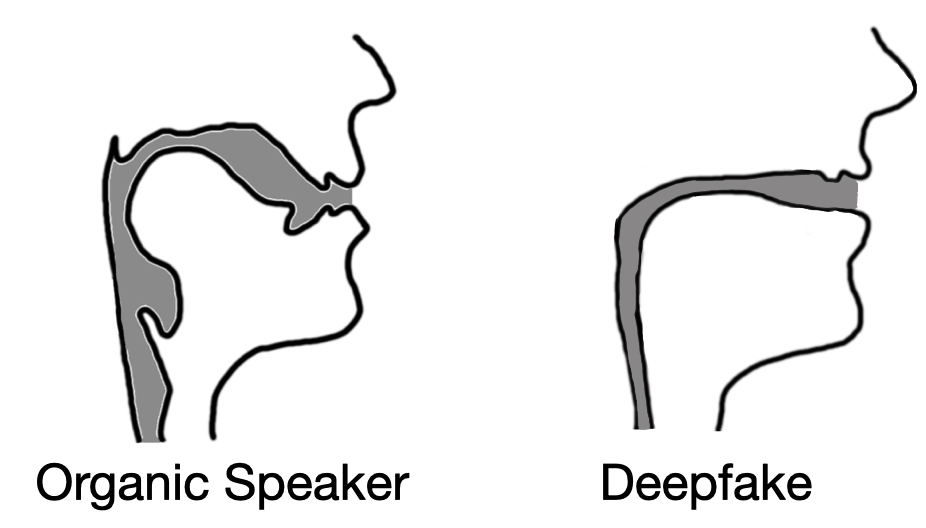
This implies that the concept could also work in reverse: vocal samples retrieved from a recording could theoretically be used to reconstruct the actual vocal tract of a speaker. However, in attempts to do so, the computer's “tract” turns out unnaturally thin and proportionate compared to a human’s, which has a broader and somewhat uneven structural consistency and shape.
Notable Examples of Audio Deepfakes
Audio deepfakes can be separated into two categories: those which are benign and created for non-malicious reasons, and those which are used in spoofing attacks.
Benign
As reported by the Antispoofing.org Wiki, audio deepfake technology can be applied in various fields: movie production, game design, automatic customer assistance, healthcare, and so on. A perfect example is online entertainment, where unnamed GAN architectures simulate voices of video game characters, politicians, music artists, and so on.
The YouTube channel Vocal Synthesis is dedicated to a series of videos in which a number of the American presidents recite the same Navy Seals Copypasta — a piece of the web folklore satirizing online threats. A similar video features a group of the American presidents performing a cover version of an N.W.A. song.
A Witcher 3 fan-made mode received widespread attention online. Dubbed “A Night to Remember,” it featured the voice of the lead character's voice actor, Doug Cockle, synthesized with a CyberVoice that is currently known as SteosVoice. Voice-cloning of other game characters has also become regionally popular, with Warcraft characters rapping in Russian language.

Though these examples were all created just for fun, it raised the question: does an actor have copyright status of their own voice as intellectual property? Could an actor have a case if their voice were used to create inappropriate material or misinformation?
Several online content creators have come close to crossing that line. The YouTube channel Corridor Crew conducted an experiment in voice hijacking when actor voices were used to create an “inspirational video” about the cultures of various states. A bogus interview between Joe Rogan and Steve Jobs was created by podcast.ai to commemorate the legacy of Apple's founder, crossing into the controversial territory of replicating a voice of a deceased person.
CereProc also experimented with this in 2008, when it recreated John F. Kennedy's speech that was supposed to be delivered in Dallas on November 22, 1963 — after his assassination. The project was challenging, as the sample material of 831 speeches wavered in quality. To overcome it, authors used de-noising, prosody modeling, and speech segment blending. Kennedy's voice was recreated with 116,777 small phonetic units in total.
Spoofing attacks
Deepfake audio is unfortunately used for deceit just as much, if not more, than it is created for entertainment. If a criminal has the ability to take any voice and manipulate it to say what they want, this opens the floodgates for disinformation, malicious content, and fraud.
At least two cases of audio deepfake attacks have been highly publicized. The first instance took place in 2019 when an energy company's CEO received a call claiming to be from the German parent company. Culprits synthesized the German chief executive's voice and successfully requested a $243,000 transfer.
A similar spoofing scenario targeted a company from UAE where culprits contacted a Hong Kong-based partnering bank. The attack was planned carefully, as the culprits had prior knowledge about an upcoming acquisition deal. They prepared emails allegedly coming from the coordinating lawyers, which resulted in $35 million getting stolen.
According to Pindrop's CEO, fraud, including phone and voice-based scams, incurs $470 million of annual losses.
How to Detect Fake Audio
Voice antispoofing methods rely on liveness detection, both active and passive. Manual detection also includes some methods.
Active
This approach requires an accessor to say a passphrase that undergoes analysis. One of the techniques is audio segmentation. It applies time mapping between the audio stream and an uttered phrase to assess genuineness. Another method is Audio-Visual Automatic Speech Recognition (AVASR). With the face points distribution model (PDM) and lip movement tracking, it can spot audiovisual inconsistencies.
Passive
A promising solution called IDLive Voice can detect spectral artifacts left by speech conversion and TTS generation, which cannot be caught by a human ear. Voice Liveness Detection or VOID spotlights cumulative power patterns of acoustic spectrograms, which helps detect replayed audios. POCO method analyzes the pop noise intrinsic to real audio — this is a phenomenon that occurs when people pronounce plosive consonants.
Manual
A person can detect a voice spoofing attack even without special tools. It's vital to pay attention to fricatives — /s/, /z/, /f/ — as TTS makes them sound more like a hissing noise — as well as phrasal timing and unnaturally long/short pauses, bizarre gliding or monotonous intonations, distortion, frequent erroneous syllable stressing, etc.
Positive Effects of Fake Audio
Besides entertainment and malicious spoofing, fake audio generation does have some positive potential uses. As in Roger Ebert's case, speech synthesis can restore a person's voice lost due to illness — rheumatoid arthritis, throat cancer, vocal cord paralysis, and many more. A synthetic voice based on the previously captured audio samples of a subject can be integrated into a neurally controlled speaking device that is capable of decoding “novel sentences from participants' brain activity.”
Not all audio spoofing relies on generated audio — a “replay attack” can use previously recorded audio which has been manipulated. To read on about audio replay attacks, click here.

References
- The "Kempelen" speaking machine
- Roger Ebert's lost voice was artificially revived with the help of voice-cloning
- Raymond Kurzweil Introduces the First Print-to-Speech Reading Machine
- Audio Deepfakes: Can Anyone Tell If They’re Fake?
- Creating Robust Neural Speech Synthesis with ForwardTacotron
- Generative adversarial network by Wikipedia
- Generative adversarial network by Wikipedia
- Fraudsters Cloned Company Director’s Voice In $35 Million Bank Heist, Police Find
- Kurzweil Reading Machine, the first TTS device
- Vocal Tract Anatomy and Diagram
- Arytenoid cartilage
- Human vocal tract
- What did dinosaurs sound like?
- Dinosaur Vocalization Study (2022) | Cretaceous Era
- Dryptosaurus vocalization is one of the hypothetical paleoacoustics reconstructions
- Deepfake audio has a tell – researchers use fluid dynamics to spot artificial imposter voices
- Vocal Synthesis on YouTube
- Six U.S. Presidents read "Fuck Tha Police" by N.W.A (Speech Synthesis) WITH MUSIC
- SteosVoice
- Lyndon Johnson's audio deepfake reciting the "Navy Seals copypasta"
- Rapping in Russian language
- Corridor Crew on YouTube
- 'Biggest breakthrough I've seen': AI creates Steve Jobs interview with Joe Rogan
- Welcome to podcast.ai, a podcast that is entirely generated by artificial intelligence
- JFK Unsilenced
- Basic phonetic units. Units of phonetics
- Fraudsters Used AI to Mimic CEO’s Voice in Unusual Cybercrime Case
- Creating Robust Neural Speech Synthesis with ForwardTacotron
- IDLive Voice (voice anti-spoofing)
- Void: A fast and light voice liveness detection system
- POCO method
- Is that video real? Fake images and videos are everywhere. Here’s how to spot them
- Fricative Consonant Sounds
- Synthetic Speech Generated from Brain Recordings
 Antispoofing
Antispoofing




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}