
Definition
Automatic Speaker Verification (ASV) is a personal verification system, which authorizes a user by their voice. A speech sample of a registered user is stored in its database, which is later compared to an input sample during the access phase. While being reliable and affordable to implement, ASV also proves to be vulnerable to spoofing attacks.
ASV includes two phases:
- User enrollment during which their voice sample is registered.
- User verification, which provides authorization to the enrolled user.

A number of Presentation Attack Instruments (PAIs) are used voice activated systems. The main spoofing tools are: a) Voice synthesis, b) Voice conversion, c) Replay attacks. Artistic impersonation is also named as a possible attack scenario. However, it cannot fully emulate characteristics of a target’s vocal apparatus and is, therefore, of minor threat to ASV. Origin of voice anti-spoofing and its rapidly developing types and preventive techniques were dictated by the urgent need of securing ASV systems, among all else.

PAIs that use speech synthesis — especially those based on deepfakes — are considered a more serious threat. Therefore, most of the proposed solutions focus on attacks performed with the help of AI. And due to the wide proliferation of the ASV systems — mobile phones, Internet of Things, online banking, telehealth — voice anti-spoofing becomes imperative, as manual fake audio detection basically can't solve the issue.
Speaker identification vs. Speaker Verification
While an ASV system provides both speaker identification and verification, there’s a feasible difference between these two groups. When put together, they constitute voice recognition modality.

Speaker identification
Speaker identification is a process, in which the identity of a person speaking is being determined. In simple terms, it provides an answer to the question of which user is speaking? At this point, it is important to distinguish known subjects from the unknown, as well as some specific user from the rest.
Speaker recognition should not rely on any text-dependent input data, otherwise it would turn into a password-based system. Instead, it focuses on how the utterances are spoken, detecting intricacies inherent to a specific user’s voice and speech: timbre, articulatory gestures, accents, intonations, pitch and amplitude, and so on.
Commonly, ASV systems are designed to recognize utterances of unconstrained speech, which are then converted into speaker embeddings — vectors of fixed and compact size that help identify a speaker and are not impacted by the length of an utterance. Among all else, they are successfully used in speaker diarization, as well as in speech synthesis.
Speaker Verification
Speaker verification basically means authentication. At this step a user, who claims a target’s identity, is either identified or rejected. To achieve the verdict, the voice sample that comes with the input data is compared with the legitimate user’s voice samples previously registered within the system. The algorithm extracts features from the claimant’s voice, while a registered vocal sample is also retrieved from the database. Then, the extracted features are matched against those of the previously registered ones. Eventually, if the matching score is equal to/higher than a pre-set threshold, authentication will be complete and vice versa.
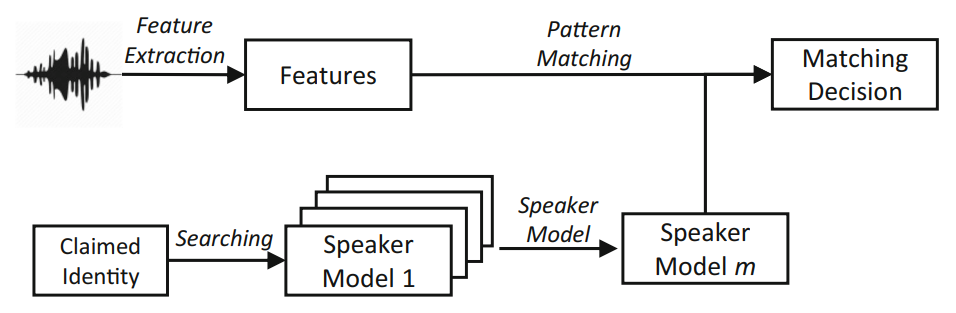
General Structure of Automatic Speaker Verification System
An ASV system analyzes both physiological and behavioral data. As for its functionality, it is separated in frontend and backend domains. The frontend part is responsible for retrieving such speech parameters (or features) as frequency, sampling rate, pitch, magnitude, and others. These features are then compared to identify signal sources, detect speaker’s uniqueness, etc. The backend part allows identifying and processing characteristics intrinsic to the speech features.
Usually, an ASV system includes the following main elements:
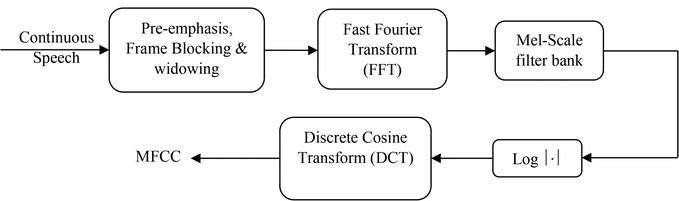
- Feature extraction. Speech signal magnitude is being reduced as much as possible to remove meaningless information — such as ambient noises — without damaging the speech signal power. An acoustic waveform is basically transformed into a parametric representation from which prosodic features are extracted. Various means are used for that: Perceptual Linear Prediction (PLP), Mel-frequency Cepstrum Coefficients (MFCC), Gaussian Mixture Model (GMM), and others.
- Speaker modeling. The goal of speaker modeling is to associate an identifier with a speech of a given user and separate them from all other, alternative speakers. For that, feature vectors that belong to the speech of that specific user are modelled. Log-likelihood ratio is estimated with the Gaussian Mixture Model - Universal Background Model (GMM-UBM) to make a binary decision.
- Pattern matching. Finally, the claimant is either accepted or rejected depending on the matching results.
It is also suggested that the speaker verification should include the normalization stage as it is able to provide better calibration, a more accurate threshold and a better performance. Liveness detection should not be omitted either as it helps to prevent spoofing attacks.
Datasets
Datasets play a vital role in designing ASV systems, especially in terms of accuracy. A number of ASV datasets were assembled for training and testing, as well as for spoof detection.
YOHO
The oldest ASV dataset, YOHO was gathered in 1989. It contains audio samples recorded at a 8kHz sampling rate and retrieved from 138 speakers uttering two-digit numbers in English.
Wall Street Journal (WSJ)
WSJ is the most popular dataset used in many researches. It’s divided into two parts: Training dataset (73 hours of speech recordings) and Testing dataset (8 hours). Gathered in 1991, it also has a WSJ1 expansion. (Alternative link to Spatialized Multi-Speaker WSJ.) Additionally, it contains transcriptions of the recordings.
TIMIT
TIMIT Acoustic-Phonetic Continuous Speech Corpus was created in 1993. It offers utterances of 10 sentences from 630 speakers recorded at a 16 kHz sampling rate.
NIST
NIST Speaker Recognition Evaluation (SRE) started in 1996 and continues to this day with SRE21 being the latest update. It offers conversational telephone speech (CTS) samples, as well as audio from video (AfV). Besides, there’s a multilingual collection of sample material.
ASVSpoof
ASVSpoof is an ongoing challenge, in which voice antispoofing solutions are tested. It also produced a number of databases.
Spoofing Attacks Against the ASV Systems & Countermeasures
There are four main types of voice spoofing attacks: impersonation, replay attacks, speech synthesis, and voice conversion.
Impersonation
Impersonation aims at reproducing intonations, mannerisms, sound length, and other prosodic/stylistic characteristics of a speaker. An impersonator has a chance to spoof an ASV system if only their voice is highly similar to the target’s voice: False Acceptance Rate (FAR) can be up to 60%.
Replay attack
In this scenario a person’s pre-recorded voice is used. It can be an audio downloaded from the Internet or a speech recording obtained without the target’s consent, etc. It is reported that in some cases Equal Error Rate (EER) can achieve a 70% rate in this scenario.
Speech synthesis
Deep learning made it possible to create highly believable replicas of someone’s voice, engendering audio deepfakes. They are seen as the most dangerous attack scenario: one of the experiments showed the FAR rising to 91% when the system was exposed to a speech synthesizer based on the Hidden Markov Model (HMM).
Voice conversion
Voice conversion allows transforming an attacker’s voice into that of a target. At the same time, the linguistic content of the speech can be fully manipulated. Experiments showed that FAR can be as high as 17% in this scenario.
Countermeasures
Various methods are proposed for preventing voice spoofing attacks, many of which focus on speech liveness. Replay attacks can be detected with the POCO method, which analyzes pop noises or with the channel difference measuring.
For deepfake audios a constellation of antispoofing solutions is proposed: dynamic range analysis of spectral parameters, phase spectrum analysis, F0 statistics analysis, etc. Supervector-based SVM classifiers and probabilistic mappings are suggested for detecting voice conversions.
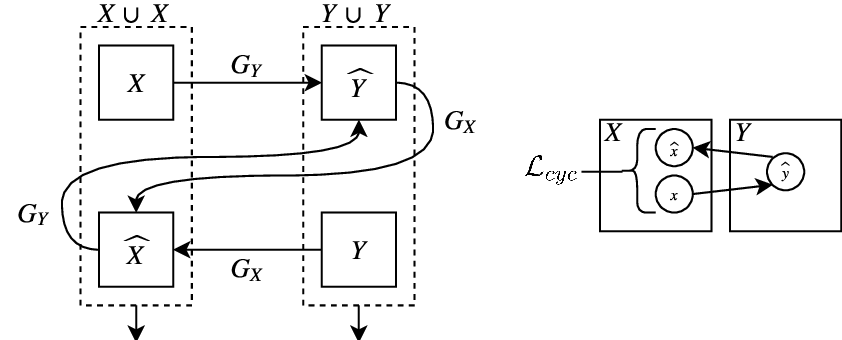
Effect of Face Masks on Automatic Speaker Verification Systems
It is noted that masks made of various materials, as well as scarves and helmets, tend to decrease speech intelligibility and acoustic properties of the voice in general. A method was proposed to improve recognition of mask-distorted speech with an ensemble of a cycle-consistent Generative Adversarial Network (GAN) and a Residual neural network (ResNet) that worked in unison with the help of a Support Vector Machine (SVM) classifier.
FAQ
Automatic Speaker Verification definition
Automatic Speaker Verification (ASV) is a popular security system which identifies a user by their voice but is prone to spoofing and presentation attacks.
Automatic Speaker Verification (ASV) is a system, which recognizes and verifies a user by their voice. ASV is avidly used due to its simplicity, customer friction reduction, and passwordless authentication.
However, the system proves to be sensitive to spoofing. A number of Presentation Attack (PA) methods exists including voice impersonation, replay attacks, voice cloning and conversion. To tackle these threats, various voice antispoofing techniques — audio segmentation, cumulative power patterns analysis — are proposed.
References
- Automatic speaker verification on site and by telephone: methods, applications and assessment
- Spoofing and countermeasures for automatic speaker verification
- ASV and its main components
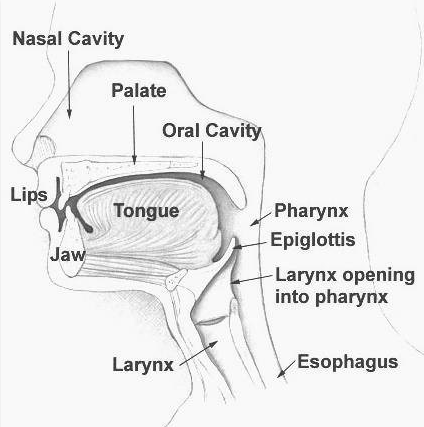
- Explainer: Why the human voice is so versatile
- Speech apparatus components make every individual’s speech unique
- What Does the Speaker Embedding Encode?
- A Review of Speaker Diarization: Recent Advances with Deep Learning
- A survey on presentation attack detection for automatic speaker verification systems: State-of-the-art, taxonomy, issues and future direction
- Prosodic features
- Perceptual linear predictive (PLP) analysis of speech
- Mel-frequency Cepstrum Coefficients
- Gaussian Mixture Model
- Speaker Verification using Gaussian Mixture Model (GMM-UBM)
- Some Commonly Used Speech Feature Extraction Algorithms
- YOHO Speaker Verification
- CSR-I (WSJ0) Complete
- CSR-II (WSJ1) Complete
- SMS-WSJ (Spatialized Multi-Speaker Wall Street Journal)
- TIMIT Acoustic-Phonetic Continuous Speech Corpus
- NIST Speaker Recognition Evaluation
- ASVspoof5
- Databases by asvspoof.org
- Voice Conversion and Anti-spoofing of Speaker Verification
- POCO method
- Preventing replay attacks on speaker verification systems
- F0 statistics for 100 young male speakers of Standard Southern British English
- Spoofing countermeasures for the protection of automatic speaker recognition systems against attacks with artificial signals
- Toward Realigning Automatic Speaker Verification in the Era of COVID-19
- Are you Wearing a Mask? Improving Mask Detection from Speech Using Augmentation by Cycle-Consistent GANs
- Cycle GAN model
 Antispoofing
Antispoofing


