
Voice Antispoofing Challenges: Goals, Milestones & Results
Voice antispoofing contests are hosted globally, to evaluate the most effective methods of preventing voice spoofing attacks.

Voice antispoofing contests have steadily been attracting attention since 2015 when the first ASVspoof challenge was introduced. Their daw began almost at the same time with the origin of voice anti-spoofing and its types, and preventive techniques. The goal of the challenge was to identify the best solution that could differentiate between real and synthesized speech, leading to prevention against spoofing attacks.
Concerns around voice spoofing have been raised together with the onset of smart gadgets: Automatic Speech Verification (AVS) is one of the most used biometric systems, which makes it especially prone to attacks by malicious actors. The threat of voice spoofing is aggravated further as voice is easier to replicate compared to face, fingerprints or other biometric modalities.
Today a number of applications, devices and even vehicles rely on voice verification: mobile banking, telehealth, transportation, private and public security, Internet of Things, and others. Therefore, voice spoofing can lead to an array of detrimental events: from money theft to espionage, smart system sabotage and potential acts of terrorism.
ASVspoof
ASVspoof is a pioneering antispoofing challenge among existing voice liveness detection contests. Organized by Japan Science & Technology Agency, Eurecom and Academy of Finland, it is an ongoing event that has taken place every 2 years since 2015. Since 2022, ASVspoof now exists as a joint workshop with VoicePersonae.
ASVspoof challenge mostly focuses on Presentation attacks (PAs) produced with speech synthesis and voice conversion. The latter technique allows disguising the attacker’s voice making it sound similar or nearly identical to the victim’s voice. This is achievable with techniques such as Dynamic Kernel Partial Least Squares Regression (DKPLS), Recurrent Temporal Restricted Boltzmann Machine (RTRBM), and others.
Four ASVspoof challenges have been hosted till now, with each producing unique results.
ASVspoof 2015
The debut ASVspoof challenge was based on the anti-spoofing (SAS) dataset v1.0, which incorporated 3,750 real and 12,625 modified speech samples. The live samples were acquired from 106 individuals without any effects or noises added to them. The spoof samples were altered with synthesis and voice conversion. Additionally, Development and Evaluation datasets were offered with a bigger sample amount.
Modification techniques ranged in sophistication. Among them were simple speech frame selection, adjusting of the first mel-cepstral coefficient (C1) for shifting the source spectrum slope, Hidden Markov Model (HMM) for speaker adaptation with a limited number of phrases, and Festvox synthesis tool. Moreover, unknown attacks were also featured in the evaluation set for added difficulty.
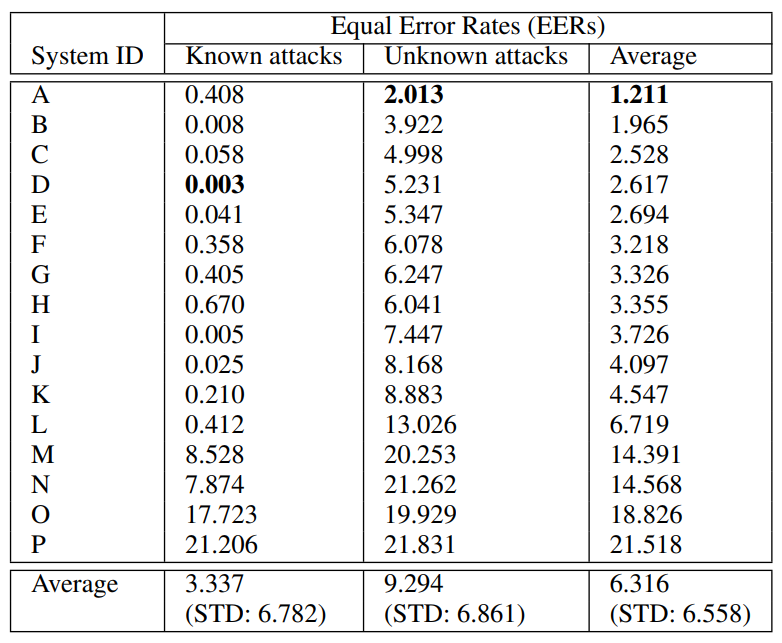
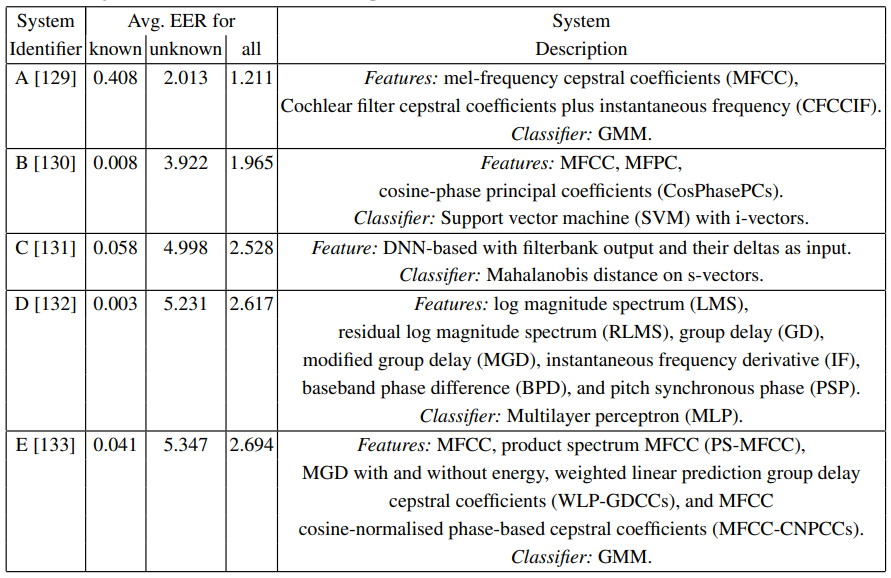
ASVspoof 2017
The follow-up challenge was based on the RedDots dataset, which contained samples recorded with Android devices around the world. Its purpose was to simulate a ‘stolen voice’ situation, in which fraudsters have access to the original voice recordings of a victim and can replay the recordings to deceive the system.
The dataset contained three partitions: Development, Training and Evaluation. They contained various utterances and ID passphrases recorded in various acoustic ambiances and with different types of smartphones.
The challenge showed that AVS performance significantly dipped when a zero-effort impostor attack was replaced with a full-scale replay attack. Primary (S) systems employed Gaussian mixture model (GMM) back-end classifier and constant Q cepstral coefficient (CQCC) features. Baseline (B) systems were baseline replay and nonreplay detectors. The system S01 demonstrated the best result of 6.73% EER.
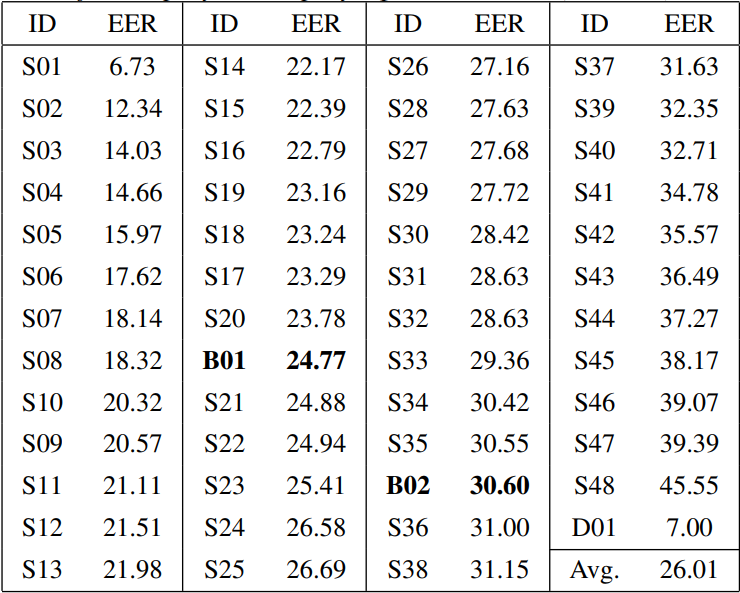
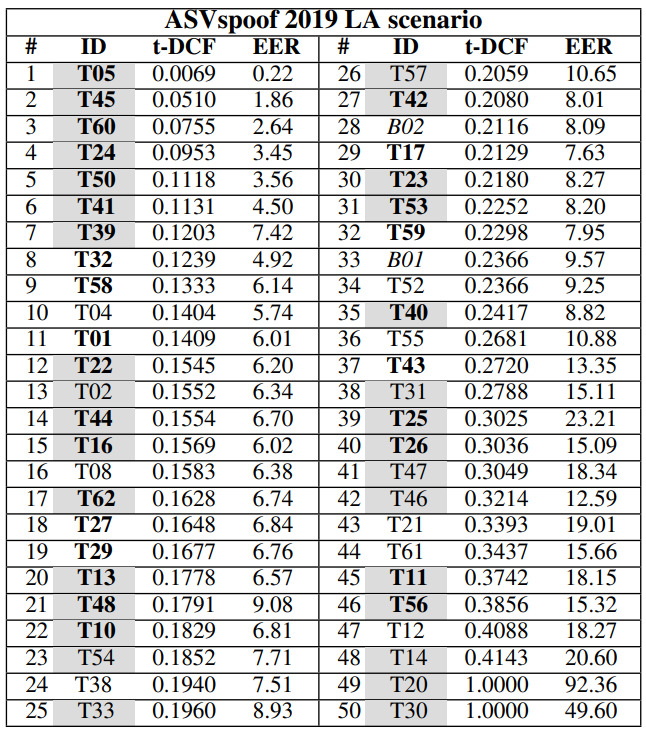
ASVspoof 2019
The third installment of the ASVspoof contest was based on the Physical and Logical Access attack scenarios. In the first case, fraudsters used a Text-to-Speech (TTS) tool that produced a realistic human voice. In the second case, attackers obtained a person’s voice recorded in any reverberating space and replayed it to the verification system.
Consequently, the dataset was based on these two scenarios and comprised Training, Development and Evaluation parts. Attacks were separated into known and unknown as well. Logical Access (LA) dataset was produced with TTS systems that featured a conventional source-filter vocoder, WaveNet-based vocoder, and other components.
Physical Access (PA) dataset comprised speech samples recorded in rooms of varying sizes and reverberant qualities, featuring 3 groups of volunteer speakers segmented for training, development and evaluation phases. The evaluation results showed that PA scenarios have a bigger EER spread than LA attacks. Moreover, PA detection does not rely on fusion strategies for better performance, while LA detection shows the opposite behavior.
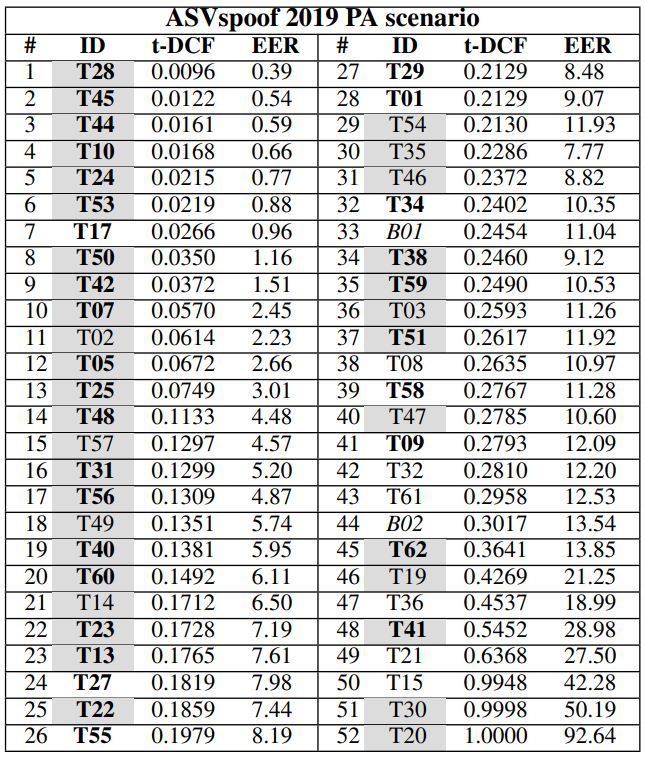
ASVspoof 2021
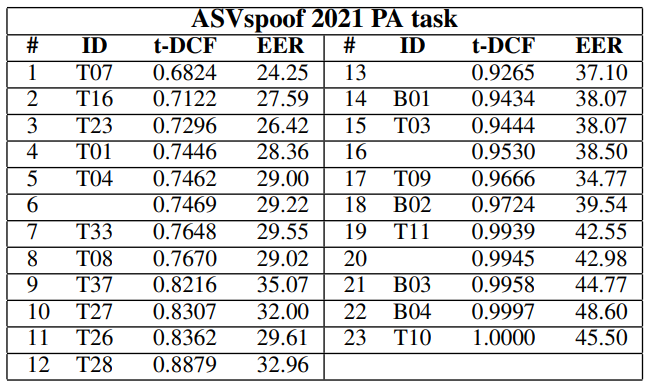
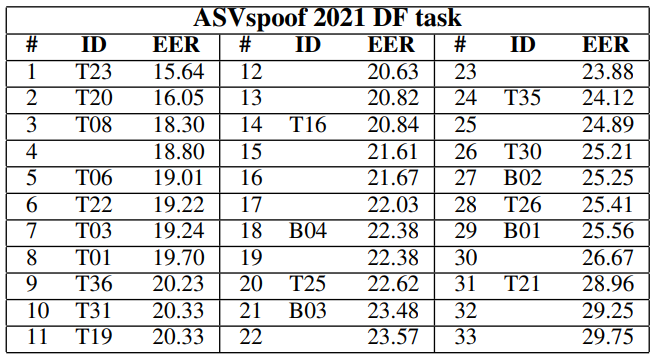
The fourth challenge focused on LA and PA scenarios, as well as on Speech Deepfakes (DFs), which are highly realistic copies of real people’s voices. Therefore, the dataset was extended with the counterfeit voice samples created with deep learning. Additionally, the 2021 contest was more stimulating, as its datasets contained more telephony artifacts, noises, reverberation types, etc.
In the Logical Access category, the best system was B03, which gave a minimal Detection Cost Function for the Tandem (t-DCF) of 0.3445. In the Physical Access category, the best result belonged to the B01 system and exhibited a minimum t-DCF of 0.9434. In the Deepfake category, the best performance was 22.38% EER demonstrated by B04.

Speaker Antispoofing Competition
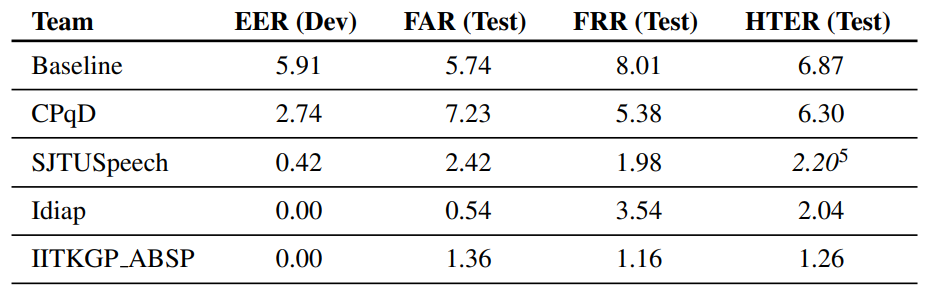
The Speaker Antispoofing Competition was hosted in 2016 and primarily focused on the replay attacks when a pre-recorded voice sample is being replayed to the microphone of a verification system.
The competition’s dataset involved two attack variations that can be described as ‘unknown’:
- First case. Speech samples were recorded with a smartphone to simulate a scenario when a person’s speech is being secretly recorded. They were then replayed to another smartphone.
- Second case. The original audios were replayed to a smartphone to simulate a situation when the digital voice recordings are stolen.
Detection techniques included various methods: cepstral mean and variance normalization (CMVN), Deep Neural Networks, Bidirectional Long Short-Term Memory (BLSTM), Mel-frequency cepstral coefficients (MFCCs) for extracting speech signal features, etc.
The test results showed that all detection systems faced difficulty in recognizing new (or ‘unknown’) attack types.
ID R&D Voice Antispoofing Challenge
ID R&D’s challenge was hosted in 2019 and offered a $7,635 prize pool. The goal was to find an algorithm that could successfully differentiate fake and real voice signals. The training data included 10,323 human speech recordings and 39,679 synthesized spoof samples. 9 teams were able to earn the ‘gold’ prize using detection solutions which are publicly undisclosed.
Spoofing-Aware Speaker Verification (SASV) Challenge
The challenge began in February 2022, setting a goal of finding the most effective countermeasure solutions (CMs) that can be integrated into ASVs, as well as help develop ensemble and single systems that can detect and reject spoof utterances. As a result, the concept of a Spoofing-Aware Automatic Speaker Verification (SASV) system was proposed. The SASV-EER metrics were selected for evaluation and participants were provided with the Evaluation and Development protocols, as well as two Baseline solutions.
For pre-training ASV and CM subsystems were employed: an ECAPA time delay neural network (TDNN), VoxCeleb2 dataset and AASIST model. Three training datasets were offered to the participants:
- VoxCeleb 2.
- ASVspoof 2019 LA train partition.
- ASVspoof 2019 LA development partition.
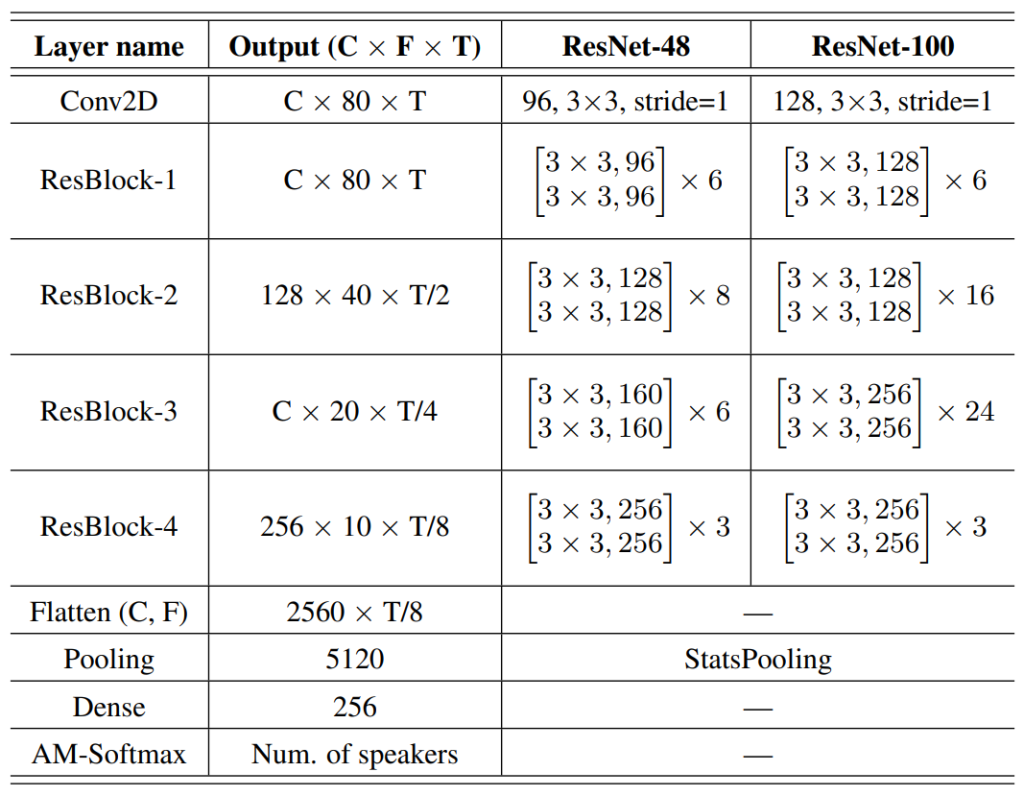
The best voice anti-spoofing solution was provided by IDVoice and had a 0.13 SASV-ERR rate. It was based on two ResNet-34 architecture modifications with 48 and 100 hidden layers and trained with Additive Margin Softmax (AM-Softmax) loss function.
FAQ
What is ASVspoof?
ASVspoof is the most remarkable voice antispoofing contest.
ASVspoof is a voice liveness detection event that started in 2015. The challenge has been hosted four times with the fifth event set to happen in 2022. The goal of the challenge is to discover the most failproof and effective methods to protect Automatic Speaker Verification (ASV) systems from spoofing attacks.
The first competition offered a dataset of 3,750 real and 12,625 modified speech samples. Each contest introduced new components to the datasets. For example, during ASVspoof 2021 the challenge tremendously grew as real-life telephony artifacts — noises, distortion, etc. — were added to both real and liveness-emulating recordings.
When did the first voice anti-spoofing contest happen?
AVSspoof challenge took place in 2015 for the first time.
The very first voice anti-spoofing challenge — AVSspoof — was organized in 2015 by a number of institutions and organizations: Japan Science and Technology Agency, Academy of Finland, Eurecom Graduate School of France, and others.
AVSspoof is an ongoing anti-spoofing competition: it’s been hosted four times and more installments are expected to take place in the future. The contest is unique for its own databases containing real and deepfake voice samples, exploration of Physical and Logical Access attacks, creative modification techniques applied to the dataset recordings, attack scenarios imitating real life, etc.
References
- Introduction to Voice Presentation Attack Detection and Recent Advances
- ASVspoof 2015: Automatic Speaker Verification. Spoofing And Countermeasures Challenge
- Telehealth: Technology meets health care
- Algorithms And Terrorism: The Malicious Use Of Artificial Intelligence For Terrorist Purposes
- Voice Conversion with Deep Learning
- ASVspoof 2015: the First Automatic Speaker Verification Spoofing and Countermeasures Challenge
- Festvox synthesis tool
- The follow-up challenge
- ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection
- ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection
- t-DCF: a Detection Cost Function for the Tandem Assessment of Spoofing Countermeasures and Automatic Speaker Verification
- Overview of BTAS 2016 Speaker Anti-spoofing Competition
- ID R&D Voice Antispoofing Challenge
- SASV Challenge 2022: A Spoofing Aware Speaker Verification Challenge Evaluation Plan
- Evaluation and Development protocols
- ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification
- AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks
- ID R&D team submission description for SASV Challenge 2022
- Additive Margin Softmax for Face Verification
 Antispoofing
Antispoofing


