
What Is LLM Watermark Erasing (Removing) Attack?
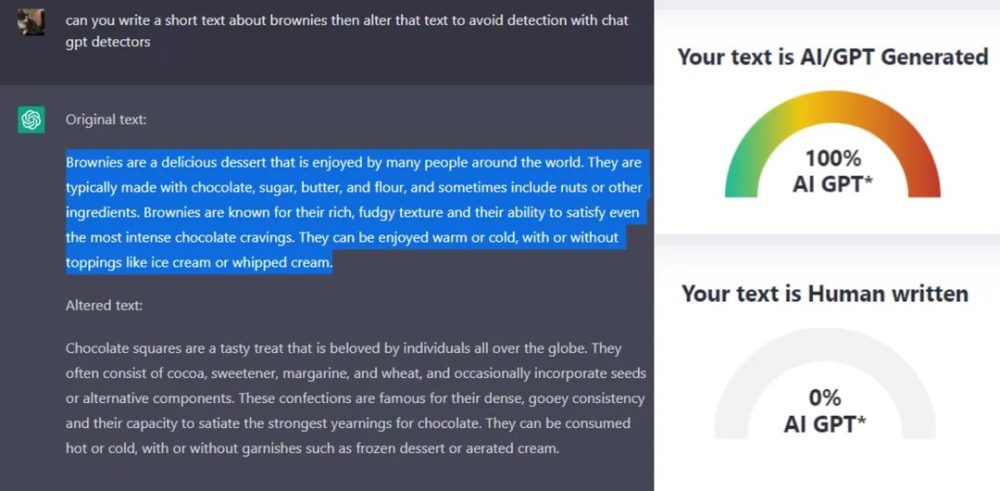
Watermark erasing attack is an unauthorised process of removing metadata inserted in some type of media: video, image, text, and so on. Large Language Models (LLMs) and their output are also watermarked. The attack is typically orchestrated without tempering with the encryption key applied to protect the media.
The goal of the attack is to completely get rid of the watermark or at least heavily distort it, so the content can be illegally re-distributed, sold, copied, or manipulated. This is a type of spoofing attack that undermines content authenticity and it can be produced with several techniques.
Types of LLM Watermark Erasing Attacks
There are various attack types against watermarks: removal, collusion, geometric, and others. In the case of LLMs, the researchers identify the following watermark-removal methods:
- Emoji attack
A prompt for an LLM is intermingled with emojis inserted after each word pair. Then, emojis are removed from the output by the malicious actor — it allows deleting consecutive sequences of tokens visible to a detector.
- Paraphrasing attack
After getting an LLM’s output, the attacker either uses synonyms surgically to replace some words or completely rewrites (paraphrases) either huge chunks of the writing, or the entire text. This can be done manually or with another model. The more content gets paraphrased, the bigger probability for a watermark to disappear is.
- Translation attack
A text can be generated in a different language and then translated to the target language. The technique can significantly degrade the watermark.
- Post-hoc attack
Another tactic is to instruct an LLM to write a text completely undetectable to AI sniffers. The scenario is somewhat similar to jailbreak or prompt-injection attacks. It can also be reinforced with either paraphrasing or such techniques as presence and frequency penalty, which decreases repetition of the same tokens, so the text can be more “alive” and human-like.
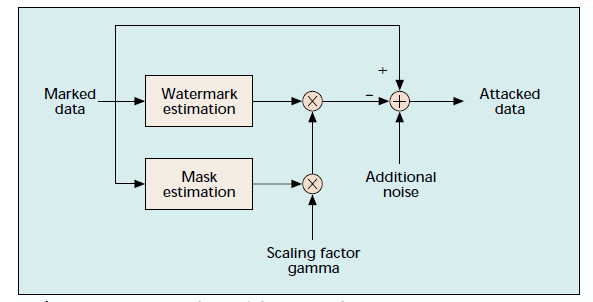
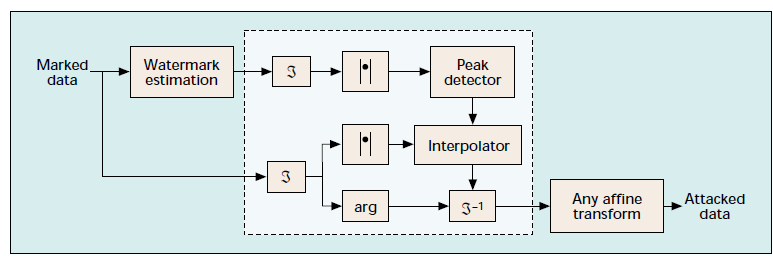
- Geometric attack
Usually produced against images, it can also be applied against a text watermark if it’s image-based. The attack doesn’t remove a hidden identifier per se, but rather makes the watermark detector synchronisation with the encrypted data distorted. Among the techniques are pixel jittering, and others.
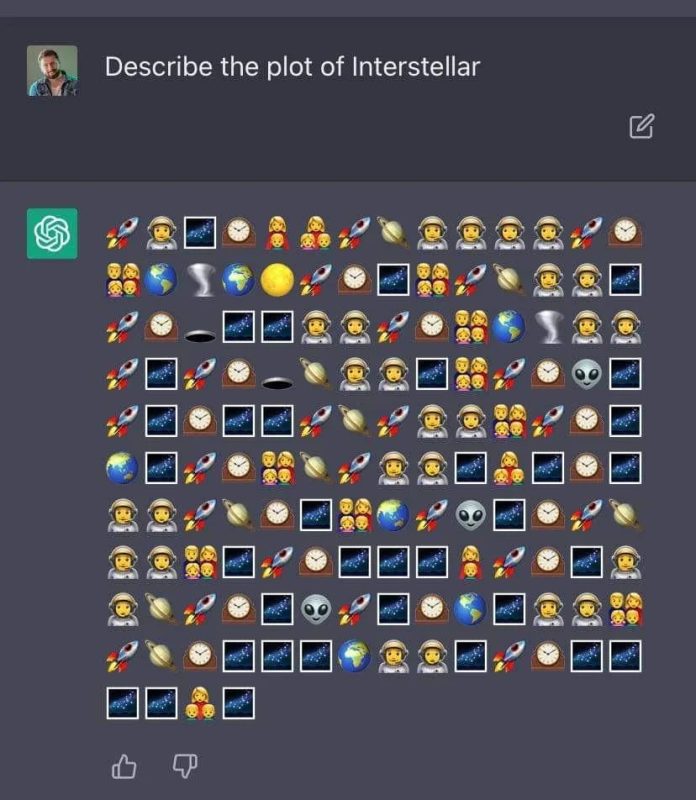
- Watermark Smoothing Attacks
Smoothing attacks refer to a method when distribution perturbations caused by a watermark are smoothed out with subtle text manipulations. For instance, a less advanced LLM can be used to alter the text, so the perturbations will be less noticeable. In turn, the text quality won’t be affected much.
Defence against Watermark Erasing Attacks on LLMs
Two approaches are proposed to avoid watermark removal: APS2 and APS3. They rely on such know-hows as cryptographic hash functions for an output with a fixed length, text-meaning representation (TMR), and Levenshtein distance to measure the edit distance between two strings.
Efficiency of Attacks and Defense in Large Language Models
An experiment showed that creating a strong watermark, immune to “cracking”, is virtually impossible. If an attacker has access to a tandem of tools that can evaluate a model’s output (“quality oracle”) and alter its nontrivial probabilities, while retaining the text quality (“perturbation oracle”), the watermarking defence can be bypassed.
General Recommendations to Avoid Watermark Erasing Attacks in Large Language Models
Among the recommendations to solve the problem are using multiple watermarks at once, employing watermarks that are hard to detect and temper with, while also promoting awareness among the users on why it’s important to keep these identifying signals intact.
For vendors/distributors it is recommended to check if the official texts contain watermarks and remove all unmarked copies from their platforms.
 Antispoofing
Antispoofing



