
What Are the Main Methods of Natural Language Watermarking (NLW)?

NLW is a technique that protects a writing with a special signal that is invisible to a regular reader. This signal usually contains metadata pertaining to the text: date of release, authorship, genre, copyright info, and so on.
Among the main NLW methods are the six categories:
- Punctuation modification. This includes punctuation marks manipulation.
- Word substitution. Words are replaced with their proper synonyms.
- Semantic modification. It relies on ambiguous word meanings, anaphora usage, and semantic role labeling — converting a natural language phrase into a machine-readable statement.
- Syntactic modification. It implies paraphrasing with the help of passive voice, clefting that breaks a bigger sentence into smaller ones, and other means.
Typos, specifically simulated ones, can also be used as part of the NLW methods.

Classical Methods of Natural Language Watermarking
The classical NLW methods include:
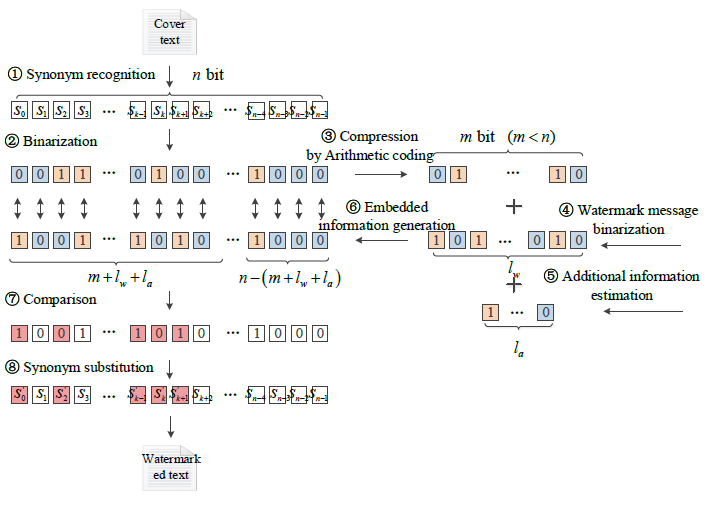
- Synonym Substitution Methods
Watermarking techniques based on synonyms have a large embedding capacity if compared to syntactic transformation. Moreover, this method is harder to detect, which makes it a popular solution. Synonym-based NLW employs a synonym database for identifying all possible word replacements in a given text, and quantization that turns synonyms into a digital sequence. Consequently, this sequence becomes a basis for the watermarking process. Watermark embedding, in turn, is regulated by a set of strict quantization rules.
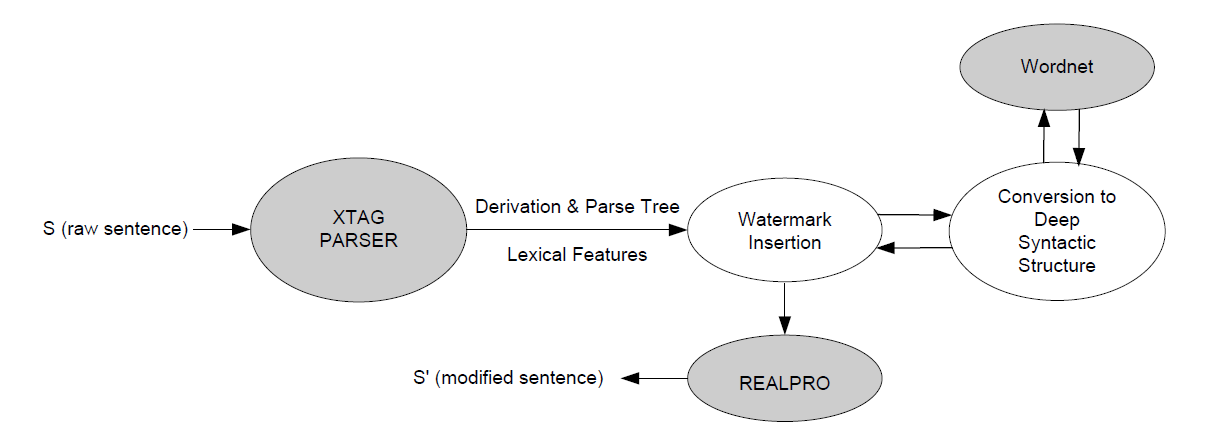
- Syntactic-Level Methods
Sentence-level NWL focuses on syntactic paraphrasing. Unlike synonym-based techniques, it cannot threaten the original meaning of a text since it doesn’t impact the lexical precision of a word. However, it can drastically influence the style of the writing.
Such a technique would feature a selection algorithm to choose sentences, into which message watermarking bits will be injected. This is done with the help of a special subset of words that are recognised as “mark-carrying”. The bedding characteristics in this case are sentence-level linguistic features: the amount of prepositions, active or passive voice, etc.
- Semantic-Level Methods
This group of methods directly focuses on the meaning of a text or sentence. In this case, watermarking is tied to the “inner qualities” of a text. A proposed technique is presupposition trigger analysis, which explores lexical items and sentence constructions, which point to some knowledge that is implied in the text and intuitively understood by the reader. The triggers include possessiveness, interrogative words, proper names, etc.
Another method is dubbed Text Meaning Representation (TMR). It focuses on such elements as topic composition and cohesion, author’s opinion/attitude, and so on. The NLW process will include turning the entire text to RMT trees, which in turn are converted to binary strings, and then watermark-matching bits should be identified.
State of the Art Methods of Natural Language Watermarking
This group of methods includes:
- Robust Natural Language Watermarking
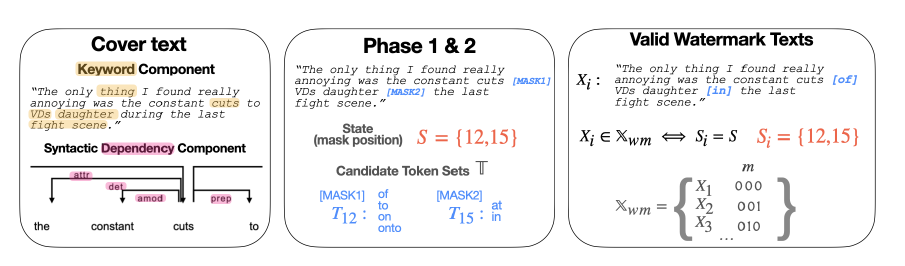
This know-how focuses on the syntactic dependencies and keywords that can be observed in a sentence. They are treated as invariant components — for example keywords that are proper nouns — and a corruption-resistant infill model is used to extract watermarks even from the considerably damaged or altered pieces of writing.
- BERT-Methods
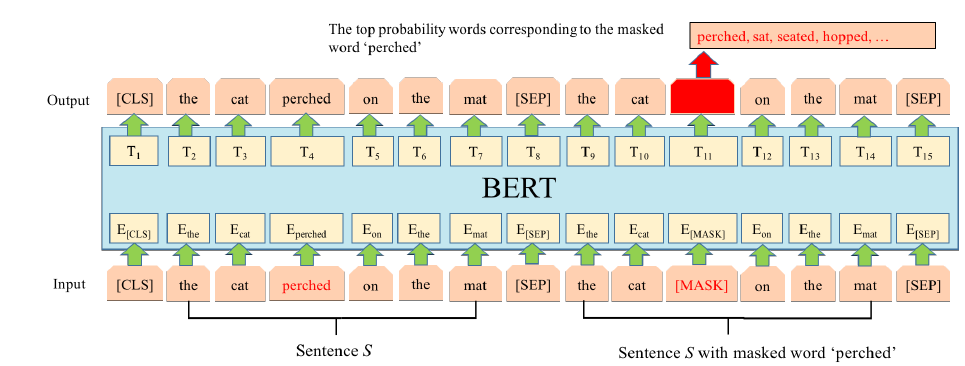
The proposed framework is based on Bidirectional Encoder Representations from Transformers (BERT) and serves to perform the Lexical Simplification task. Its goal is to find simpler synonyms to the complex words present in the original writing via the Simplification Candidate mechanism.
- Lexical Substitution Methods
This method employs lexical substitution performed with an auto-regressive encoder-decoder paraphraser.The paraphraser is used to leverage all possible synonyms of a target word. Then the system searches for the watermark traces in the context and performs an exchangeability test to make sure that the text is watermarked.
Keyword Substitution Scheme and a Prediction Error Expansion Algorithm (KSPEE)
KSPEE focuses on extracting keywords from a text, which allows detecting position of the watermark embeddings. It employs a Masked Language Model capable of selecting appropriate keyword synonyms based on the semantic context.

Automatically Learning Models
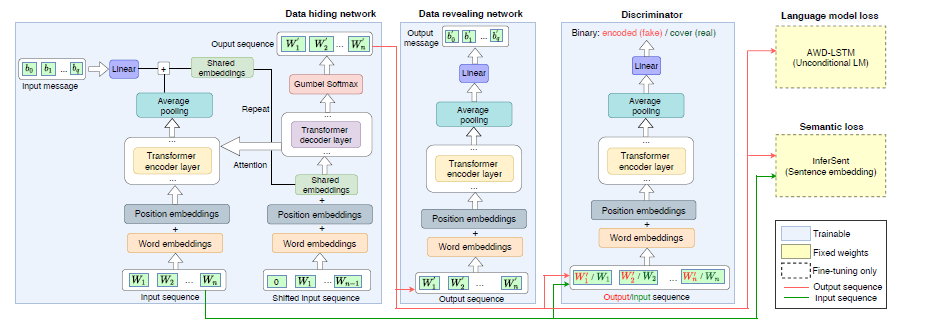
The Adversarial Watermarking Transformer (AWT) is a deep learning solution that includes a duo of the hiding and revealing networks responsible for message encoding and decoding. They are trained in an ensemble against a discriminator, which leads to a generation of an elusive text watermark that virtually doesn't impact the linguistic component of the writing.
 Antispoofing
Antispoofing



