
How Do AI-Generated Text Detectors Work?
AI detectors search for specific signals left by Generative AI. They include:
- Rhythm analysis. A parameter called “burstiness” refers to the varying sentence length in writing. While human text often has an inconsistent tempo, AI tends to write more stably.
- Unpredictability. AI’s plots and narratives are more predictable than human-written content.
- Emotional content. Some human texts — news articles, essays, fiction — display strong emotional content which AI cannot replicate.
- Structure. AI seems to have a tendency to express the same rephrased idea more than once.
- Word choice. AI often employs unnatural or bizarre lexicon.
However, an opinion by the authors of this 2024 study states that the more parameters a generative model has, the more challenging it will be to detect its presence.
The Main Methods of AI-Generated Text Detection
There are several major approaches to detecting AI texts:
- Statistical Metrics-Based Methods
- GLTR

Giant Language Model Test Room, or “GLTR,” is a visual-based tool that analyzes word probability, words’ absolute ranks, and predicted distribution’s entropy. Together, they help analyze word sampling distribution and context of writing. It is reported that human accuracy at detecting AI texts has risen from 54% to 72% with GLTR’s help.
- DetectLLM-LRR
DetectLLM-LRR is a zero-shot method, meaning it can work with data it has never seen before. Log-Likelihood Log-Rank Ratio (LLR) relies on log rank and log-likelihood data. The problem is that synthetic texts have more noticeable log than log likelihood, which helps expose them.
- DetectLLM-NPR
Normalized Log-Rank Perturbation, or “NPR,” focuses on perturbations observable in a text. These perturbations refer to small changes — like usage of synonyms or sentence structure — that increase the overall log rank score. Synthetic writing suffers even more from such changes, making it easier to detect work created by AI.
- Intrinsic Dimensionality Method
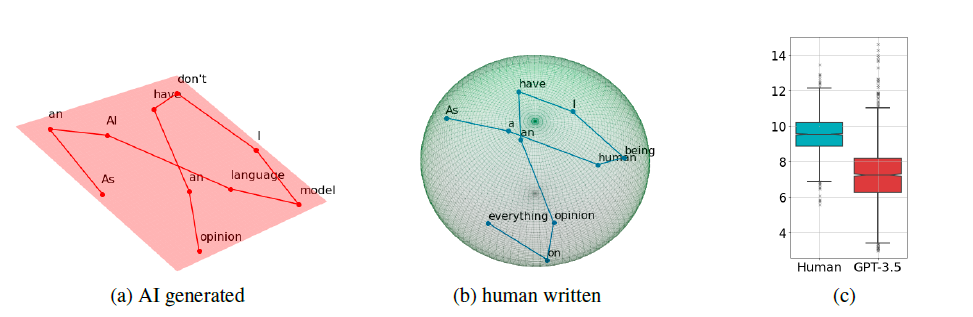
This method relies on a persistent homology dimension theory that can accurately measure the dimension of text samples by using the intrinsic dimension as a score. Intrinsic dimensions imply a number of variables that constitute a minimal data representation.

- Divergent N-Gram Analysis
Divergent N-Gram Analysis, or “DNA-GPT,” focuses on the idea that GenAI produces identical text throughout numerous generations, while human writing displays a more versatile distribution. As an experiment showed, this zero-shot method outperforms the ZeroGPT model.

- DetectGPT – Method, Based on Log Probability Function

DetetcGPT is a novel approach which does not need training datasets, watermarking, or a specifically trained classifier. Instead, it explores the negative curvature regions found in the log function of a model — an area where AI-generated texts usually sit.
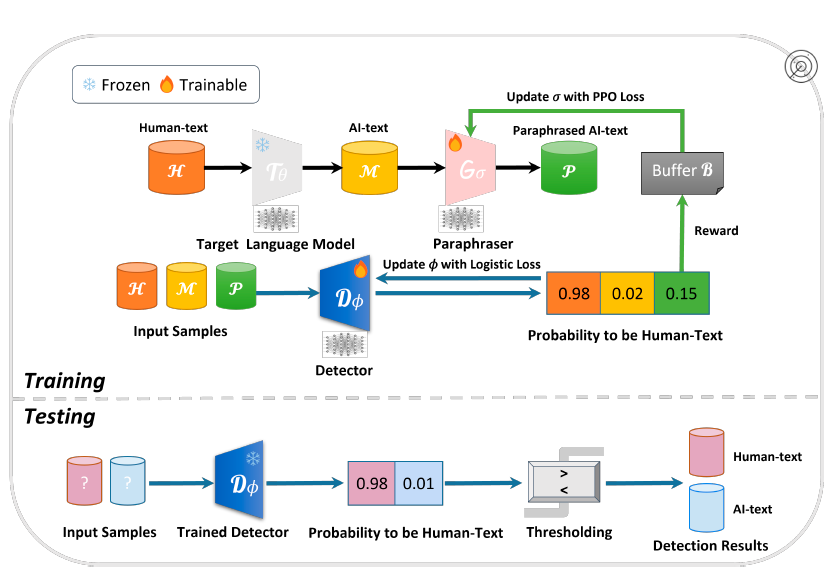
- RADAR: Detector-Paraphraser Joint Training Method
RADAR presents a peculiar detection architecture. It consists of two main components: detector and paraphraser. They are strengthened with adversarial training and exchange feedback between each other to get better results. It leads to a “cat-and-mouse game” similar to that in a Generative Adversarial Network.
Watermarking LLMs
An alternative approach suggests using invisible watermarks that can be detected only with a secret key. This sequence-based key will be known only to the generation and detection solutions, and no visible degradation will be produced to the text.
Using Transformer-Based Classifiers
Perhaps the most famous instance of a classifier detector was OpenAI’s AI Classifier, which at first could demonstrate only a 26% accuracy. Eventually, it was taken down, as its performance rate was infinitesimal for a decision-making tool. However, during another experiment, a RoBERTa-based model managed to outperform GLTR at classifying human-produced and AI-synthesized answers to various questions.
To read more about AI text detection research and the accuracy of the tools currently available, read our next article here.
 Antispoofing
Antispoofing



