
What Are Adversarial Attacks in Natural Language Processing (NLP)?

Adversarial attacks in NLP are a malicious practice of altering text with slight perturbations which can lead to a poor or inadequate performance of a text-based AI system. These perturbations include deliberate misspelling, rephrasing and synonym usage, insertion of homographs and homonyms, back translation, and so on.
Primarily, these attacks aim to poison the datasets that NLP systems are trained with. Eventually, they can give incorrect results when recognizing, analyzing, or translating a text. It can be used for manipulating source information, sabotaging international communication, bypassing spam filters, and more.
A known case of a machine translation system hallucinating occurred in 2017 in Beitar Illit, Israel, when Facebook's built-in translator incorrectly interpreted a phrase written in Arab, which led to a wrongful arrest of a Palestinian man.
Types of Adversarial Attacks in Natural Language Processing
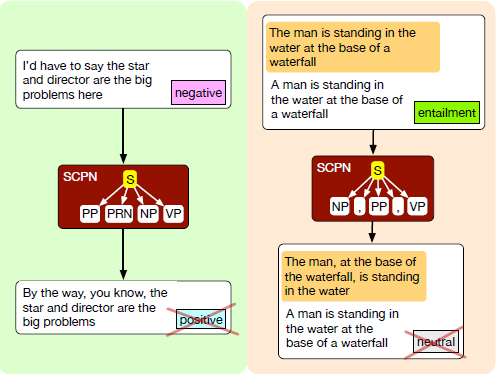
There are several attack classifications when it comes to NLP. Among them are:
- “High-Level” Attacks
Unlike in other scenarios when perturbations remain invisible to a human — such as pixel noises in a picture — text cannot be altered that easily. This is because words are discrete tokens and all changes will be instantly noticeable. High-level attacks refer to rephrasing with the minimum of word replacements of the input text, while preserving semantic and syntactic similarity of the original writing. It should be noted that in this case similarity doesn’t equal original meaning — it functions as a disguise to convey a radically distorted meaning of the initial text.

- “Low-Level” Attacks
Low-level attacks rely on deliberate typos and character replacement in a text. This method allows to retain visual similarity, and it’s done in two ways to keep the attack subtle:
- Making as few character replacements as possible.
- Inserting human-like typos that look organic at the first sight.
As a result, such an attack can impact performance of an LLM model with a reported performance decrease of up to 82%.

Tools for Attacks in NLP
A selection of adversarial tools have been designed to test robustness of the NLP systems.
- DeepWordBug

DeepWordBug is a spoofing algorithm for generating text perturbations in a black-box setting. It can be used for sabotaging a classifier accuracy of an NLP system, showing that it can drop to as low as 20% in the case of the IMDB movie reviews dataset.
It’s based on a Recurrent Neural Network (RNN) enhanced with Long Short-term Memory (LSTM), a scoring function for selecting word replacements without having to rely on gradients, the tandem of temporal score/temporal tail score, and so on.
- TextBugger
TextBugger is an attack framework that retains a high level of semantic similarity: up to 97%. It relies on a complex algorithm that injects both word and character-level perturbations. It also employs space insertion inside the words, swapping neighboring letters, replacing bona-fide characters with visually similar symbols, and so on.
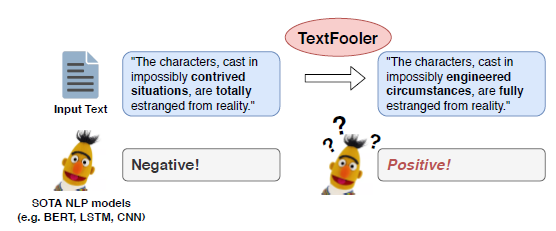
- TextFooler
TextFooler is a relatively simple method, which focuses on keywords that convey the meaning of a text with the Word Importance Ranking. Then, the most suitable word replacements are found to fit the context and maintain semantic similarity, which makes an attacked model to make erroneous predictions.
- ReinforceBug
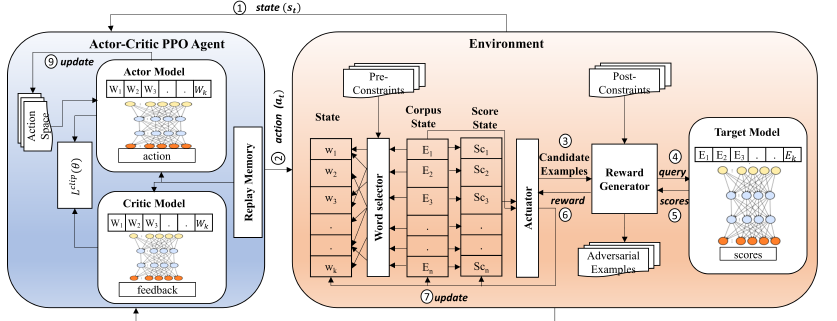
ReinforceBug is an NLP-spoofing tool that relies on reinforced learning enhanced with a Word selector, Actuator, and other components that help finding the most fitting word perturbations.
- DIPPER
DIPPER is an 11B parameter paraphrase generation model that is capable of paraphrasing a text, while taking into consideration its context and lexical heterogeneity. Its attacks successfully bypassed GPTZero and some other detectors.
Examples of Combatting Adversarial Attacks in NLP
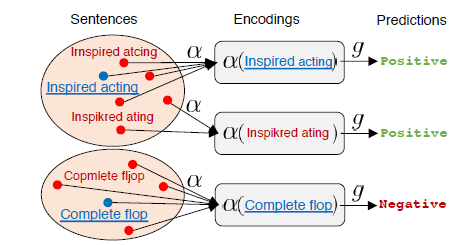
Among the tools designed to tackle NLP adversarial attacks are RoBen based on robust encoding for sentence mapping to a discrete encoding space, a method based on visual character embeddings, rule-based recovery, and adversarial training to detect the so-called “leet speak”, in which letters are replaced with digits, and others.

 Antispoofing
Antispoofing



