

The problem of bias — related to age, ethnicity, or race — has been discussed in relation to AI since robust facial recognition models have become widespread. Currently, the problem can be also observed in the way the text detectors function — they are suspected to be biased towards non-native English authors.
In turn, this bias results in detectors erroneously classifying texts written by non-native speakers as “AI-generated”. A major 2023 study conducted by the Stanford university confirms that such a correlation exists, even though some AI detection providers disagree with their view.
Do AI-Detectors Have the Same Accuracy in Different Languages?
It appears that AI text detectors may face a problem of identifying human-made content written in foreign languages. The issue springs from two main factors:
- Lack of training data. Only 20 languages are reported to be high-resource: English, Mandarin, Russian, and others. It means they have plenty of data — media, literature, or entertainment — for training a Large Language Model (LLM) or text detectors. Other languages, even spoken in a country of a high-resource language — like Uyghur in China or Nheengatu in Brazil — stay underrepresented.
- Linguistic nuances. Each foreign language has a unique grammar, as well as other distinctions that are radically different from those observed in English. Even some of the English dialects — like the Tangier Island dialect — can display linguistic uniqueness that may reduce AI detector’s accuracy.
Meanwhile, most of the existing LLMs were trained on the “general U.S. English”, which implies the standard variant of the language observed in books, TV programmes, films, etc. Another noticeable hindrance is the detector’s flaw that makes a tool fail to recognize an overly polished AI-text.

Experiments to Determine Bias in Non-English Generated Texts Detection
A number of experiments were orchestrated to reveal the possible accuracy bias in text detectors.
- Gate2ai Experiment
Gate2AI produced content with the GPT models on select topics like Is AI a friend or Foe? The six tested tools were GPTZero, CopyLeaks, Content at Scale, and so on. The results showed a somewhat reverse effect when most of the AI-detectors labeled synthesized texts as human-written, giving numerous false positives.

- Stanford Study
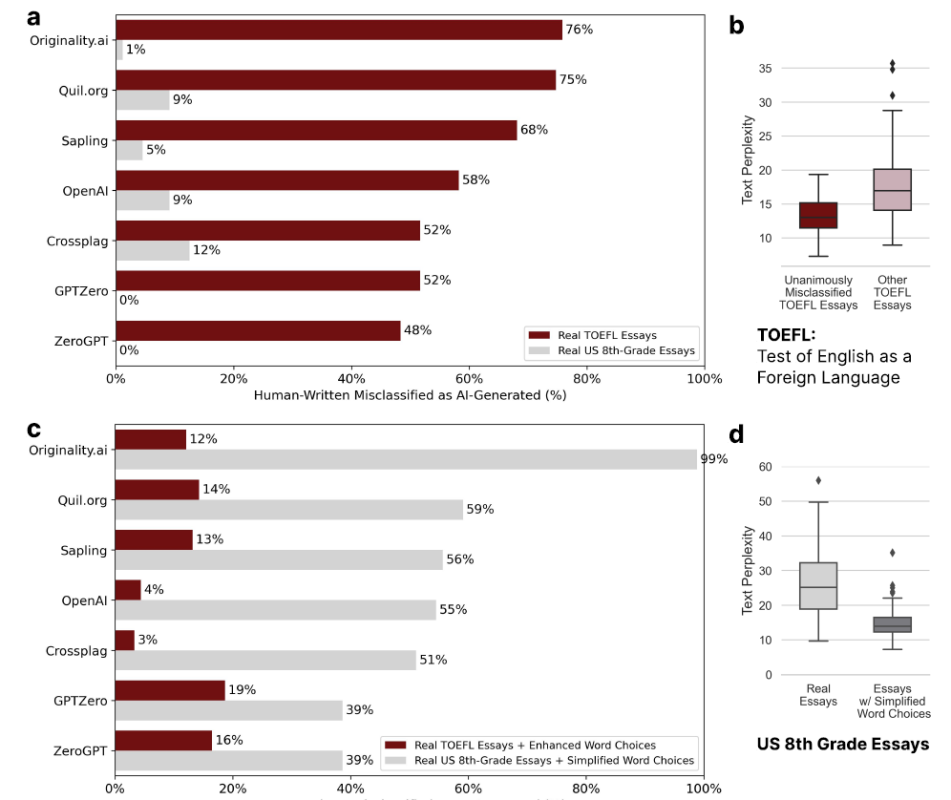
The test features 91 human-written essays borrowed from a Chinese educational forum and 88 essays authored by American eighth-graders taken from a Hewlett Foundation dataset (ASAP). As it turned out, the “American” essays were detected with an almost impeccable accuracy, while more than a half of the “Chinese” texts were identified as AI-produced: 61.22% false positives.
The test received some criticism from Orginality.ai — a project that offers AI detection services. It stated that it was “flawed” due to insufficient sample size, barely comparable sources with a confounding variable in the face of age differences, as well as a lack of updated detection technologies used in the experiment.
In response, the company had their own test, displaying the confusion matrix analysis approach. According to Originality, 1,526 of human-authored texts were correctly identified and only 81 got misclassified.
- Educational Testing Service Study
This study claims that selection of an appropriate dataset plays the key role. To train the model, the authors used the Graduate Record Examinations (GRE) data samples to successfully detect student-written texts and exclude the possibility of bias towards non-native English speakers.
- Influence of Machine Translation from Foreign Languages into English on Detection Accuracy
The test featured a number of human-composed texts previously unexposed online and machine-translated from several European languages. While the initial writings were predominantly identified as human (96%), their translated versions accuracy decreased by 20%. Presumably, artifacts left by the translating model could cause the increased error rate.
Possible Solutions to Avoid Bias against Non-Native English Writers in AI-Detectors
Apart from using a more suitable dataset composed from texts by actual students, it is also recommended to increase perplexity of the writing. This means that non-native English authors should try more diverse and rich linguistic variability when preparing a paper: this allows mitigating the predictability of a text, which AI detectors see as a definite “red sign”.
 Antispoofing
Antispoofing



