
Why is AI-Generated Content Detection Important?

Content produced by Large Language Models (LLMs) lacks human expertise and understanding, which often makes it unreliable and even dangerous. A GenAI model, ChatGPT is known to provide false and harmful medical advice, discriminative statements, incorrect legal information, and so on.
Besides, it can be used for making fake news, writing academic content, generating flawed computer code, or employing it as a weapon for scam activities and smear campaigns. Therefore, the ability to detect generated text content is of key importance.

Datasets Used for Generated Text Detection
Several datasets and initiatives exist to train detection models, evaluate LLM-based responses in terms of quality and safety, as well as help real people sharpen their ability to detect LLM-generated texts.
- Real or Fake Text (RoFT)
Real or Fake Text (RoFT) is a platform, where guests are challenged to locate the boundary when human-written passages are replaced with the machine-created content in a single text. With this gamified process, authors managed to reveal that only 15,8% of all participants can correctly identify machine-content so far.
- Human ChatGPT Comparison Corpus (HC3)
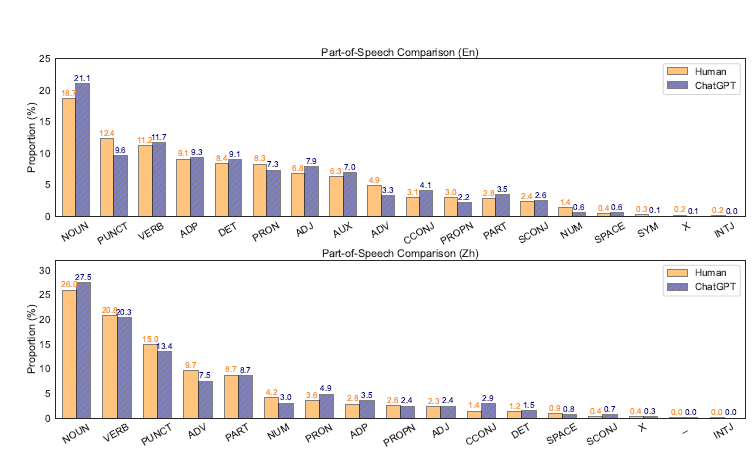
The dataset contains two major data corpuses:
- Human-based. It features public question-answering datasets and Wiki sources.
- Generated. Answers are provided by ChatGPT-3.5, with additional requests and conditions.
Turing test and Helpfulness value were featured as primary metrics for separating human answers from those by AI. As it turned out, ChatGPT’s answers have a pristine structure, are longer in size, and may contain fabricated facts. Human answers often shift to similar or distant topics, contain informal speech and emotional expressions, and also may seem more subjective.

- IDMGSP Dataset
The dataset includes human-authored scientific works, AI-generated abstracts, introductions, and conclusions, as well as writings co-authored by humans and artificial intelligence. The purpose of the study is to train a classifier that can detect generated articles on science with nearly perfect accuracy.
The Logistic Regression (LR) and Random Forest (RF) classifiers showed a 90% accuracy at distinguishing human and AI content when tried against the test dataset. Meanwhile, the RoBERTa model demonstrated a 75% accuracy at spotting papers co-authored by humans and AI. However, the fake materials were generated with GPT-3 and SCIgen, which lose in comparison to more advanced GPT-4 and upcoming ChatGPT-5.
Human Detection vs. Machine Detection Experiments
Human prowess at detecting synthesised texts in comparison to AI-detectors has been put to test in a number of studies.
- Experiments with Scientific Writing
A group of experiments were hosted with a focus on scientific papers. The results showed that human reviewers pay attention to the writing style, which is artfully mimicked by the AI. However, generated papers aren’t always clear on goals and methods of the research, which separates them from human authors. At the same time, human-written papers can be even more formulaic, as observed by volunteers.
Another study shows that humans are unable to differentiate AI and genuine writing whatsoever, while specialised models can detect at least a portion of them.
- Experiments with Online Reviews
As observed by the Yale School of Management professor Balazs Kovacs, both humans and AI tend to mistake them for feedback written by actual people. Interestingly, readers see the AI-reviews as “superhuman”, which implies that they deserve more trust than real person’s comments.
It is speculated that believable AI-generated reviews can be used for manipulating market and consumers, launching smear campaigns against rivals, or stirring artificial excitement around a specific product.
 Antispoofing
Antispoofing



