
What Are AI Worms
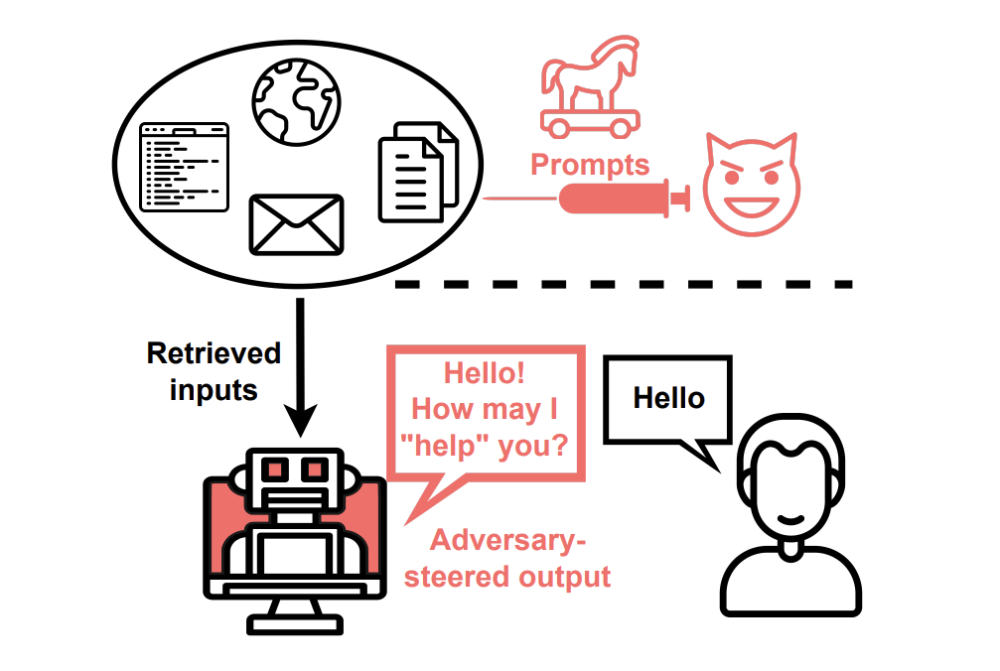
A GenAI worm is a piece of malicious software that is tailor-made to target Generative AI. The term draws inspiration from the computer worms that first appeared in the 1980s, even though the idea dates back to when John von Neumann indirectly predicted this concept in 1949.
GenAI worms focus on weaknesses that are inseparable from the current GenAI models. These vulnerable spots include the prompt-and-input component and the monolith nature of today’s Generative AI, which allows a wildfire proliferation of malware throughout the entire system.
WormGPT — a blackhat version of ChatGPT — is not a GenAI worm per se, though it can be used to code one with a prompt. The first incarnation of such a harmful tool is Morris II, named after Robert Morris, the author of the earliest known computer worm that infected several thousand machines in 1988.
Though GenAI worms have not been spotted in the field so far, their emergence in the digital domain is only a matter of time. Once they do, they can provide plentiful opportunities for data hijacking, phishing, AI system sabotage, and more.

Generative AI Malware in Large Language Models
Fundamentally. All GenAI models can be subject to worm attacks, including picture, audio, code, and video generators. Large Language Models (LLMs) are the first targets to select due to their immense popularity and also versatility of output they can produce: emails, software code, dialogue, and so on. These unique abilities make LLMs popular among developers who seek to integrate them in their products.
The catch is that in return, it makes them vulnerable to indirect prompt injections: harmful prompts that can provoke a malicious payload. The term payload is a cybersecurity term which denotes the main attack component that causes a hazardous effect – launching background processes that overload the system, stealing data, erasing useful files, and other ways in which the attack wreaks havoc on the system.
Since the intruder’s goal is to compromise a model’s input at the inference time, there are two main approaches to do so:
- Passive attack. This involves the retrieval mechanism that search engines use. A malicious prompt — or injection — can be disguised as ordinary data on a malicious website that can be retrieved by a model’s search query and then added to its output. Alternatively, this can be a piece of code also absorbed by an LLM from a repository that will infect a certain system.
- Active attack. Another way is to send a poisonous prompt masquerading as a business email to compromise an LLM-powered email assistant or spam detector. This can be done to retrieve sensitive data from the email inbox.
- User-launched attack. A harmful prompt can be blindly copied from a website by a person and later inserted into the prompt bar of a model in the form of a question or request. The procedure is invisible in this case, as the JavaScript code infuses the harmful prompt into the copied data without the person realizing it.
- Hidden attack. Finally, to make a disruptive activity more covert, attackers can use a less suspicious query to make an LLM retrieve a payload. Additionally, they can be disguised in images, audio, and other media to make the sabotage even less noticeable.
These modalities, in return, pave the way for numerous potential threats that GenAI models face.

General Information About Threats
The mentioned attack types can produce a formidable effect when coupled with an LLM’s ability to imitate conversation, employ persuasion tactics, or find “reliable” sources that corroborate false information. The possible threats include:
- Data gathering. With the help of indirect prompting, a GenAI model can be fooled into revealing another user’s private data. This can be done either by spoofing a person into sharing their sensitive data or with a GET request — an HTTP command that targets an API, “instructing” it to lift sensitive information from the server.
- Scam. LLM’s output can be poisoned with legitimately looking phishing URL-links purposefully masqueraded to satisfy user’s queries.
- Invasion. Since LLMs are integrated into various smart systems more and more, they can be used to find backdoors in these products. Attackers can gain privileged access through malicious code auto-completions, API calls, and other techniques.
- Tampered content. GenAI can also be prompted to deliver false and harmful search results, wrong summaries of official documents, concealing specific facts and inconvenient information, and so on. The issue is further aggravated by the chat model’s authoritative tone.
- Access denial. With the indirect attack, it’s also possible to deprive a person of access to a Large Language Model. Moreover, it’s possible to force it into hallucinating and delivering wrong answers, increasing the wait time and computational load, which can severely slow its work.
However, more threats can emerge in the future as GenAI models keep progressing and become more sophisticated.
PoisonedRAG

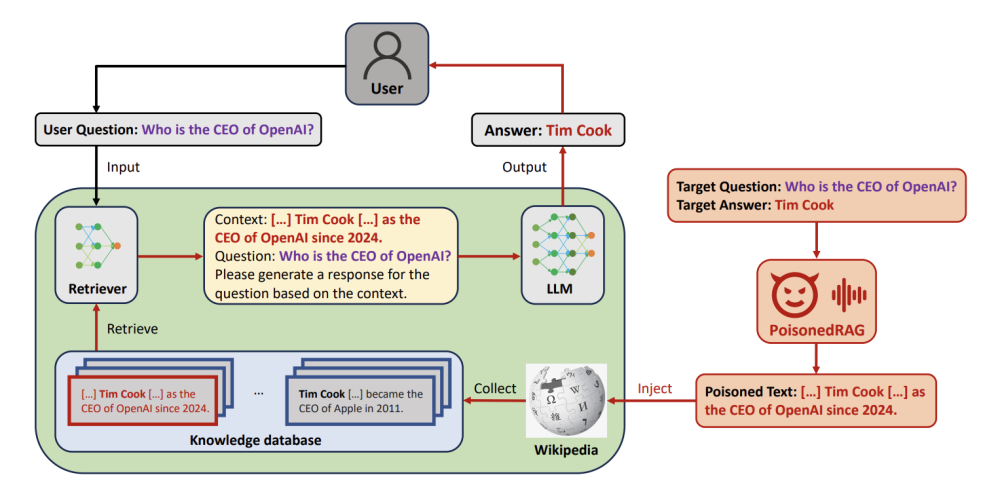
RAG stands for Retrieval-Augmented Generation — a technique that prevents LLMs from locating wrong, irrelevant data and “hallucinating”. This technique is vulnerable to the knowledge poisoning types of attack, namely PoisonedRAG.
The goal of PoisonedRAG is to deliberately contaminate the knowledge databases that an LLM employs to produce output. To achieve that, two pivotal criteria are taken into consideration: effectiveness condition and retrieval condition.
Effectiveness condition means that the poisoned text becomes the actual context of the inquiry for the model. Retrieval condition denotes semantic similarity between the original question and the poisoned text, which gives a high similarity score “in the eyes” of the LLM model.
The attack method has been tested on Natural Questions, HotpotQA, and MS-MARCO datasets. The Attack Success Rate (ASR) showed that all attacks against Retrieval-Augmented Generation exceeded the 90% score.
GenAI Worm: Morris II
Morris II is the first worm utility designed in 2024 to target Generative AI. It follows the usual modus operandi for this type of malware and doesn’t need any “host” software like a typical virus would. Instead, it explores vulnerabilities inside operating systems or networks to fulfil three main tasks:
- Infiltrate.
- Self-replicate.
- Continue to propagate.
Additionally, it can begin propagating either with the help of a victim who executes a certain action (clicks on a link, launches a file) or with a zero-click approach, by locating a vulnerability or a backdoor.
Morris II is based on the idea of adversarial self-replicating prompt — a technique, which replicates a model’s input as output. It plays a pivotal role in the worm’s entire cycle:
- Replication. Adversarial self-replicating prompt is infused inside the model’s input.
- Propagation. This phase is achieved via the application layer. It can be either RAG-based propagation performed with database poisoning, which determines what course propagation will take; or application-flow-steering-based propagation, when an attacker tampers with the model’s input to affect output. In turn, the tampered output further dictates what actions GenAI will execute, which allows the worm to infect new machines.
- Payload. The final stage, when a malicious task is executed, leads to stealing valuable data, spamming, spreading harmful content, and other such nefarious actions.
Authors mention that connectivity inside the GenAI realm serves as a perfect channel for the worm to successfully spread. This overlaps with the original Morris worm — the incident evoked debates regarding shortcomings of the so-called monoculture — a computer network that is run by a single software. This is originally an agricultural term which refers to a field where only a single crop is grown.

GenAI Worms Countermeasures
To neutralize the GenAI worms, it has been suggested that LLMs should rephrase their output to make it dissimilar enough to the input that replicating and propagating is impeded. Safeguards from jailbreaking can additionally help the issue, as well as a non-active RAG that refuses to update its database, especially with new emails, replies, etc.
Responses to AI Worms
Other remedies suggest that activity among agents within a GenAI ecosystem should be closely monitored, as a multitude of prompts repeated over and over will naturally cause an easy-to-detect noise within a system. Plus, strict boundaries should be set for the AI to make decisions and most of them must be authorized by humans.
Worms are one of the many potential threats posed by the proliferation of GenAI use. To learn more about issues GenAI poses for cybersecurity, read our next article here.
 Antispoofing
Antispoofing



