

When we think of generative AI, we think of it as a recent phenomenon. However, you may be surprised to learn that the first time music was generated using AI was when Soviet mathematician Rudolf Zaripov conducted his 1960 study, "An algorithmic description of the process of music composition."
In it, he described a simple algorithm of generating a music piece:
- It should follow a three-part structure (A-B-A.)
- Each separate phrase (i.e., 8 bars) should end on one of the tonic triad notes.
- Wide intervals — starting with a perfect fifth — can’t be repeated twice in a single phrase.
- A number of successive notes shouldn’t be more than 6.
In 1965 — at the age of only 17 — Raymond Kurzweil presented a mini-computer he had constructed from telephone relays that played the role of logical circuits. It had a built-in algorithm that could detect musical patterns and reproduce them to create original melodies.

Music and audio AI synthesis is a task much more challenging than, for example, generating images or text. That is due to music’s inherent complexity — tempo, genre, monophony or polyphony, instrument choice — and context, which implies rhythmical and harmonic consistency.
Despite this complexity, generative AI audio models are becoming so realistic, it can sometimes be difficult to distinguish AI-generated audio from “genuine” audio. Before we delve into how to detect AI-generated audio, we first have to understand the scheme for how music is created, prevalent models for text-to-audio, and the latest methods for synthesizing generated audio and music.

General Scheme of Generating Audio
As reported by Flavio Scneider in his paper “Archisound: Audio Generation with Diffusion,” 1 second of 48kHz stereo audio requires as many resources as generating a medium-resolution picture would. That means a variety of audio synthesis solutions can be used to make the goal achievable.
Audio generation includes two principal domains: speech and music. You’re probably already familiar with the first component if you’ve heard of text-to-speech technology.
Speech and Text-to-Speech (TTS)
One of the earliest techniques to create artificial speech was the Statistical Parametric Speech Synthesis (SPSS), which consisted of three stages involving conversion of input text to linguistic and acoustic features.
Generative Adversarial Networks (GANs) reduced the process to just two stages with the use of deep vocoders that can produce waveforms from linguistic features.

Diffusion models (DMs), which are pioneering the field of image synthesis, show promising results.
Some examples of Audio Diffusion Models (ADMs) include:
- Diff-TTS. This model applies Denoising Diffusion Probabilistic models (DDPM) for generating el-spectrograms. To do this, it uses a text encoder to extract contextual info to align it with the length and duration predictors.
- ProDiff. This focuses on generator-based parameterization and knowledge distillation, as these functions allow the production of a high-quality output at a lower computational cost.
- DiffGAN-TTS. This is a hybrid solution, which couples a pre-trained generative model as the acoustic generator and an active shallow diffusion used for denoising based on the coarse prediction. As a result, it takes just one step for the solution to produce high-quality audio.
- Grad-TTS. Based on Iterative Latent Variable Sampling (ILVR), this is an adaptive model that mixes latent variables with the vocal sample. As a result, this allows zero-shot speech generation – meaning the model learns how to classify speech outside of its given set of classifications.
Other ADMs include NoreSpeech, Guided-TTS 2, Grad-StyleSpeech, and more.
However, one of the most promising alternative models AudioStyleGAN (ASGAN), uses the concept of modification to adaptive discriminator augmentation for better training and suppressing aliasing by mapping a single latent vector to a sequence of sampled noise features using a disentangled latent space design.
It is substantially faster than other contemporary diffusion models, and it’s also more “creative”; even without explicit training, ASGAN can successfully perform voice conversion and speech editing.
Music and Text-to-Audio Synthesis
Current music AI generation is mostly based on GAN solutions, so we’ll discuss some of them in detail.
C-RNN-GAN
With a hybrid architecture, it merges a GAN for modeling data with four real-valued scalars at every data point — time, tone length, frequency, intensity — and a Recurrent Neural Network (RNN) is used as a baseline for predicting successive tonal events.
Trained on a MIDI corpus of classical music, it has undergone backpropagation through time (BPTT) and mini-batch stochastic gradient descent with L2 weights regularization.
Freezing is used to balance Discriminator and Generator, while feature matching creates an internal representation to match real music data. As a result, the model has managed to produce music with an impressive degree of polyphony.

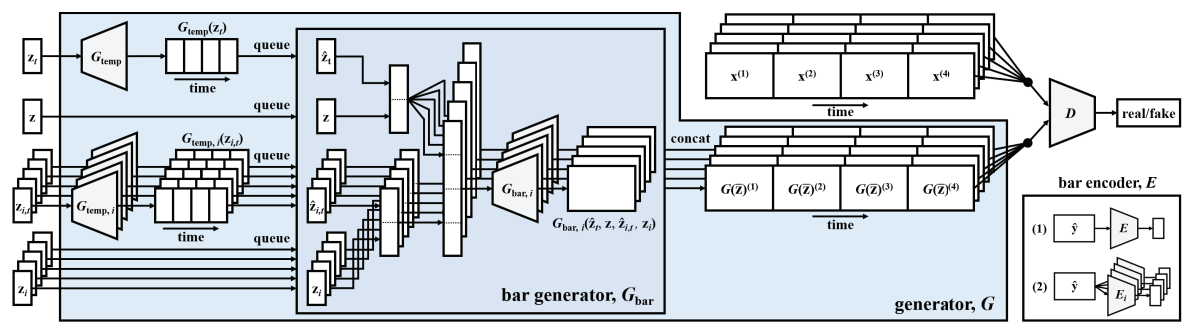
MuseGAN
Beats are at the heart of music, so MuseGAN is built based on that fact. It is a multitrack sequential music generator which focuses on bars — the number of beats at a particular tempo — as the main composition units. It features a piano-roll, which is an instrument used in many digital audio workstations (DAWs) for placing notes over time steps.
Trained on a Lakh MIDI dataset, MuseGAN includes two temporal subnetworks in the Generator’s domain: Temporal structure generator and Bar generator for creating sequenced piano-roll data. It can extract latent vectors containing inter/intra-tracks. They are then chained together with the time-independent random vectors before being fed to the Bar generator, which delivers piano-roll sequences.
MeLoDy
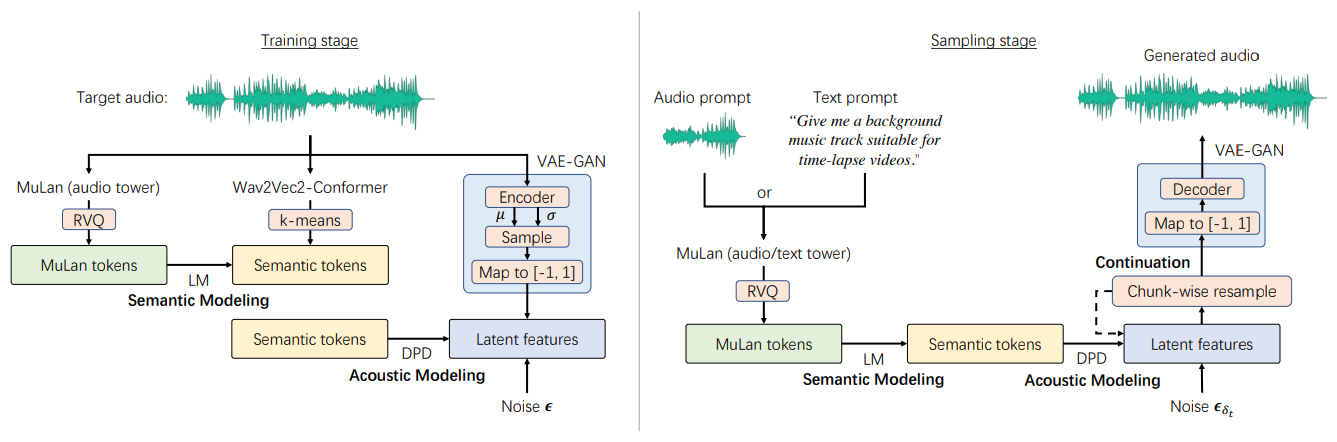
MeLoDy takes a much different approach. It is a complex solution that includes a Language Model-guided diffusion framework, novel dual-path diffusion (DPD), which is a variant of diffusion probabilistic model in continuous time, and an audio VAE-GAN for learning continuous latent representations for synthesizing quality music tunes.
Representation learning relies on Audio VAE, MuLan, and Wav2Vec2-Conformer. Semantic synthesis and acoustic synthesis rely on a language model (LM) and DPD, respectively, as they allow modeling contextual relationships and velocity prediction. Basically, MeLoDy’s architecture allows generating audio with a reference prompt.
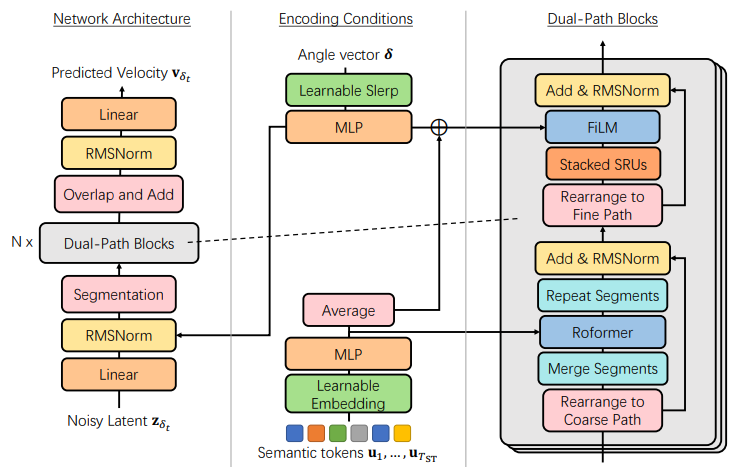
DiffSinger
DiffSinger is a Singing Voice Synthesizer (SVS) based on a diffusion model. It includes the parameterized Markov chain employed for noise conversion into mel-spectrogram, additionally shaped with a music score. With the help of variational bound optimization and a shallow diffusion mechanism, DiffSinger can deliver impressively realistic results.
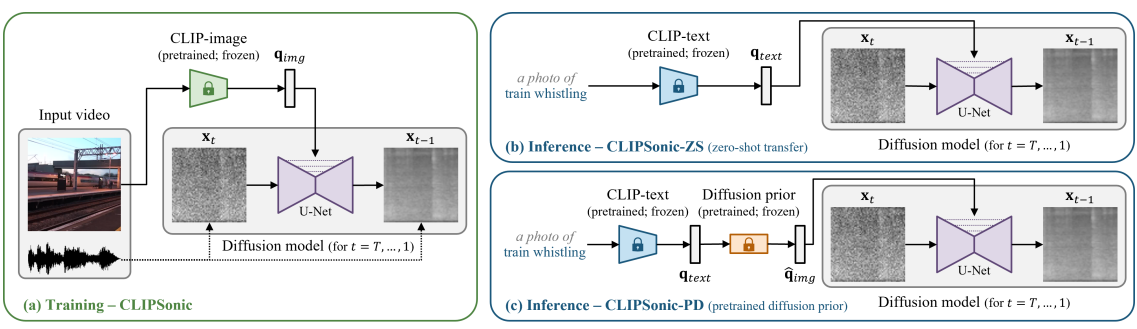
CLIPSonic
CLIPSonic is a Text-to-Audio (T2A) model that employs a spectrogram-based diffusion model to produce audio files. It does this by synthesizing the audio mel-spectrogram from the provided video footage.
From there, an encoder is used to turn an image into a query vector, which is used as a conditional signal to guide the Denoising Diffusion Probabilistic model. Finally, a BigVGAN is used to reverse mel-spectrograms into audio. You can achieve T2A by leveraging language-vision embedding space learned.
Alternative solutions include Musika, TANGO, Foley Sound Generator, and others.
Text-to-Music
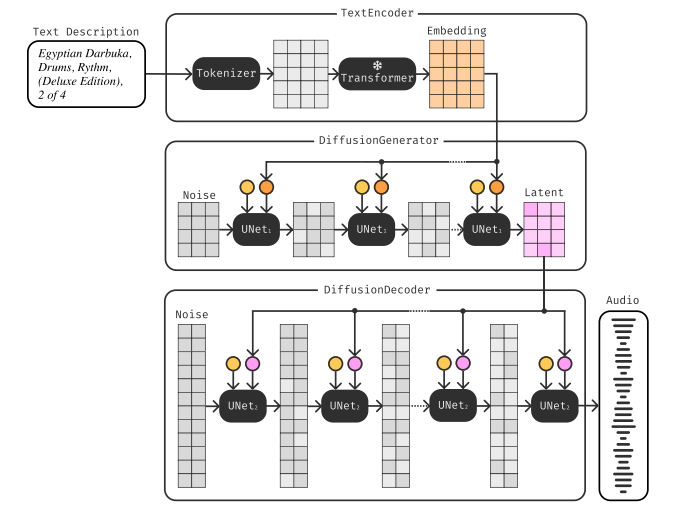
Mousai is a Text-to-Music (T2M) model capable of composing long bits of music at a 48kHz sample rate. It is based on a repurposed hourglass convolutional only 2D architecture (U-Net). Mousai’s version is enhanced with conditioning and attention blocks, as well as other new elements.
Mousai employs a cascading latent diffusion approach and Denoising Diffusion Implicit Models (DDIMs) for signal denoising. It also uses a diffusion-based autoencoder to achieve more compressibility and Diffusion Magnitude-Autoencoding (DMAE). The latter provides a diffusion autoencoder that also plays a role of a vocoder. To maintain textual elements, it resorts to a T5 language model and classifier-free guidance (CFG).
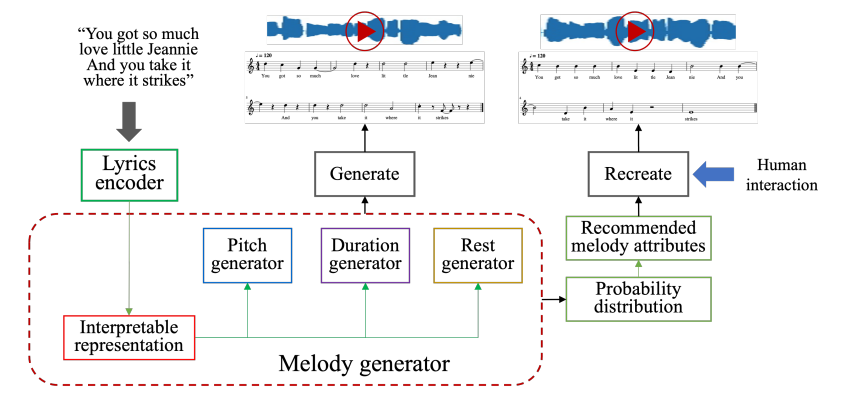
Another solution is based on a GAN optimized with the Gumbel-Softmax component, which prevents non-differentiability at the stage of melody generation. With the help of the Skip-gram models, the solution can dissect the user’s lyrical input and arrange a suitable musical accompaniment.
Other Audio Generators: Honorable Mentions
Diff-Foley is a Video-to-Audio (V2A) model based on an LDM enhanced with contrastive audiovisual pretraining (CAVP). Any-to-Any uses Composable Diffusion (CoDi) that can work with multiple modalities and their combinations: text, audio, video, and others. Meanwhile, Dance2Music-GAN is an adversarial multi-modal framework that can compose a soundtrack to a silent dance video.
Detecting Generated Audio
Now, to take this information we’ve learned about generative AI and apply it to detection: how can we differentiate synthetic audio from genuine audio?
The proposed method would be to employ Automatic Speaker Verification spoofing datasets (ASVspoof 2019) and frequency spectrogram analysis performed with a Convolutional Neural Network (CNN) that can produce max pooling and dropout to avoid overfitting.
Then, a softmax function would be used to obtain two detection scores that would help reach a verdict as to whether the audio is real or fabricated.
References
- Ural (computer), From Wikipedia
- CYBERNETICS AND THE REGULATION THEORY. An algorithmic description of a process of musical composition
- Raymond Kurzweil developed a machine algorithm that could reproduce music patterns
- Statistical Parametric Speech Synthesis
- C-RNN-GAN: Continuous recurrent neural networks with adversarial training
- A piano roll example used in FL Studio DAW
- MuseGAN: multi-track sequential generative adversarial networks for symbolic music generation and accompaniment
- Efficient Neural Music Generation
- CLIPSonic: Text-to-Audio Synthesis with Unlabeled Videos and Pretrained Language-Vision Models
- Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
- Interpretable Melody Generation from Lyrics with Discrete-Valued Adversarial Training
- That time in 1965 when a teen Ray Kurzweil made a computer compose music and met LBJ
- ArchiSound: Audio Generation with Diffusion
- Diff-TTS: A Denoising Diffusion Model for Text-to-Speech
- Denoising Diffusion Probabilistic Models
- ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech
- DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
- Iterative Latent Variable Refinement
- Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech
- NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-robust Expressive TTS
- Guided-TTS 2: A Diffusion Model for High-quality Adaptive Text-to-Speech with Untranscribed Data
- Grad-StyleSpeech: Any-speaker Adaptive Text-to-Speech Synthesis with Diffusion Models
- GAN You Hear Me? Reclaiming Unconditional Speech Synthesis from Diffusion Models
- What Is MIDI? How To Use the Most Powerful Tool in Music
- Backpropagation Through Time
- Digital audio workstation
- The Lakh MIDI Dataset v0.1
- DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
- Musika! Fast Infinite Waveform Music Generation
- Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
- Text-Driven Foley Sound Generation With Latent Diffusion Model
- The Hourglass Network
- Diff-Foley: Synchronized Video-to-Audio Synthesis with Latent Diffusion Models
- Any-to-Any Generation via Composable Diffusion
- Quantized GAN for Complex Music Generation from Dance Videos
- Frequency Domain-Based Detection of Generated Audio
- Reason: Using the Vocoder
 Antispoofing
Antispoofing




#/media/File:Ural-1_front_view.jpg){kind=link}
{kind=link}
{kind=link}