
Danger of Fake Text News and Social Bots in Social Media
Fake news has been considered a tangible threat since at least 2016, when the US presidential elections were affected by fake tweets, news articles, and blog posts coming from both inside and outside the country.
Now, false information on social media is known to cause grave consequences that can result in public unrest, like the sparks of politically-motivated violence in Gabon or Myanmar, or disinformation that resulted in the “Indian Kidnappers” case. The highly-visible results of conspiracy theories and false science spread during the Covid-19 pandemic highlighted how severe the issue had become.
With the introduction of Generative Pre-trained Transformer models (GPT), producing such content has become especially accessible. These GPT models allow anyone to create fake news with a credible and authoritative tone, and even in a journalistic style, on a massive scale. According to Statista, in most countries, social media play the role of the primary news outlets, which only exacerbates the problem.
One such social media platform which has been used to proliferate this fake news is X (formerly known as Twitter). The platform is rife with bots posting false news headlines and misinformation which can be disseminated to a wide audience. As such, researchers have concentrated their efforts on Twitter in particular when determining the best ways to learn how these bots operate, how to identify them, and how to ultimately prevent their disinformation from spreading amongst the public.
Text Generation Methods
Machine Generated Text (MGT) can be produced using several techniques:
- Markov chains + RNN. This combines a stochastic model, which allows creating state tokens that help synthesize a text. The Recurrent Neural Network is added to choose the next token, while preserving knowledge about the preceding tokens thanks to its loop architecture.
- Long Short-Term Memory (LSTM). An LSTM is a type of RNN, so it works similarly. However, it can focus on the essential text data while ignoring the vanishing gradient problem, which usually occurs when backpropagation and gradient-based learning methods are involved in training a model.
- GPT. GPT is based on Transformer architecture, which employs self-attention technique to process input data: this means that it lets the pieces of input data interact with each other so the most “valuable” input can get the highest attention score. Pre-trained means that the model received preliminary training on a large corpus of texts with the help of unsupervised learning methods. In this training, the model extracts latent patterns from a writing on its own. For example, GPT-3 was trained on 500 billion words from the Common Crawl data hub.
As of now, GPT methods dramatically exceed all other text-generation techniques, mainly thanks to their superior zero-shot learning capabilities: a GPT model can even understand and “dissect” data it has never seen before.
Datasets for Social Media Bot Detection
A number of fake text datasets with samples drawn from social media exist, mainly focusing on posts found on X (formerly known as Twitter.) For instance, Cresci-2017 contains 6,637,615 tweets, as well as a large scope of bot activity examples: social spambots, traditional spamming, as well as Sybil attacks — a type of spoofing also known as “sockpuppetry”. The datasets include Cresci, The fake project, HSpam14, Chao, VirusTotal and PhishTank, Free4ever1, and others.
- TweepFake
TweepFake is a corpus combined from deepfake and occasionally real 25,572 tweets. For that purpose, a heuristic search has been orchestrated to detect X/Twitter profiles, which might use various deepfake technologies for posting, including GPT-2. The dataset features a balance between human profiles and their bot-operated copies, as well as fake text grouping according to their origin: GPT, RNN, and others.
- Botometer
While being a popular tool for detecting synthesized tweets, Botometer is also a massive repository of fake text datasets, all dedicated to Twitter. It includes Political-bots-2019 featuring automatic political accounts, Cresci-2015 with fake/real accounts, Astroturf with “hyperactive political bots”, and so on.
Identification Methods and Models
A variety of detection techniques have been proposed to reveal fake social media texts. However, their evolution has been a slow one.
History of Social Bot Detection Techniques
Previously, bot detection relied on four parameters:
- Activity. Robots tend to post more frequently.
- Metadata. Launch date, followers, uploaded content, etc. can be indicators of bot activity.
- Content features. Human content is more erratic and diverse than that from bots; bots tend to have content restrained to only a few set topics.
- Networking. Bot accounts seem to form “coalitions” and support each other on a platform, which can make them easier to detect.
However, due to Large Language Models (LLMs) and other generative AI tools, bot accounts have become more sophisticated and human-like over time. To detect them, various methods are suggested, somewhat relatable to deepfake forensics.
- TL-MVF Model
TL-MVF Model is a complex tool that combines transfer learning, Text-to-Text Transfer Transformer model for data cleaning, like punctuation removal, and sentence tokenization. RoBERTa — an improved version of Google’s Bert — is another component. It can analyze both left-to-right and right-to-left texts and learn context information given in a certain tweet.
- Combined Deep Learning with Word Embeddings Model
This is a two-fold approach which combines feature extraction and word embeddings, which are a method of grouping words that have a close meaning: “plane — jet — aircraft”.
For feature extraction, it employs Term Frequency (TF), which analyzes how often a certain word appears in a text. It is further supported by the Term Frequency - Inverse Document Frequency (TF-IDF), which helps the model understand what words are the most important and give them respective weights.
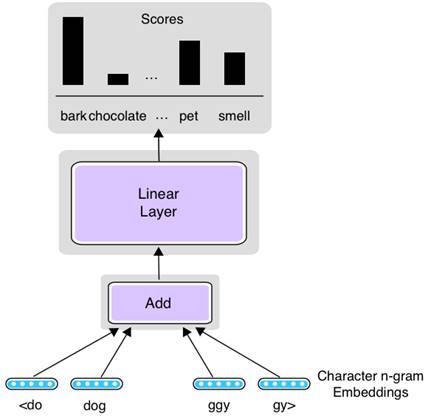
For word embeddings, researchers suggest using FAIR’s FastText for text categorization and FastText Subword, which breaks down words into their smaller parts; this helps the model analyze even those words that were not used in training.
- Detection of DeepFake Text with Semantic, Emoji, Sentiment, and Linguistic Features
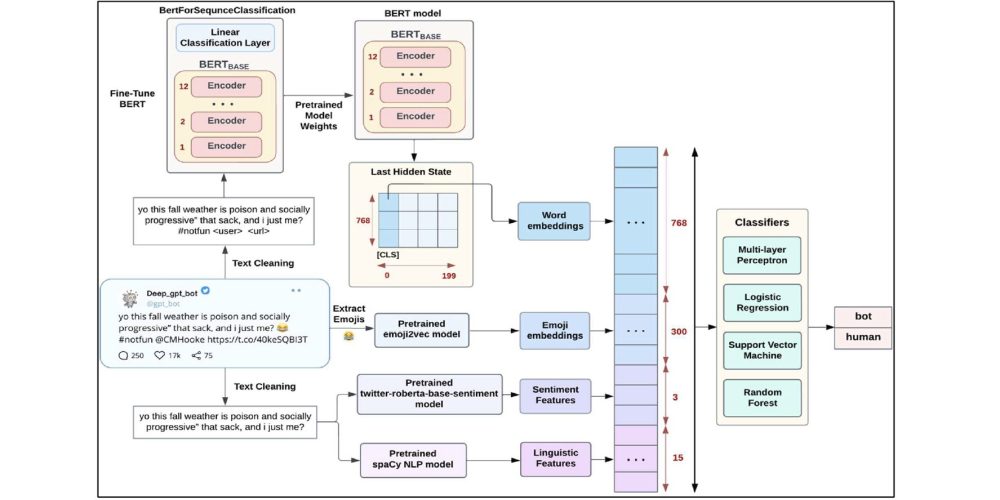
This is a comprehensive approach which focuses on the additional linguistic features present within the text. These would include positive, negative, or neutral sentiment, semantic features of a tweet, emoji usage, analysis of adjectives, nouns, punctuation, and other linguistic features. The model itself is based on BERT, with addition of Multi-Layer Perceptron, logistic regression, support vector machines, and random forest.
- NLP Method for Bot Identification
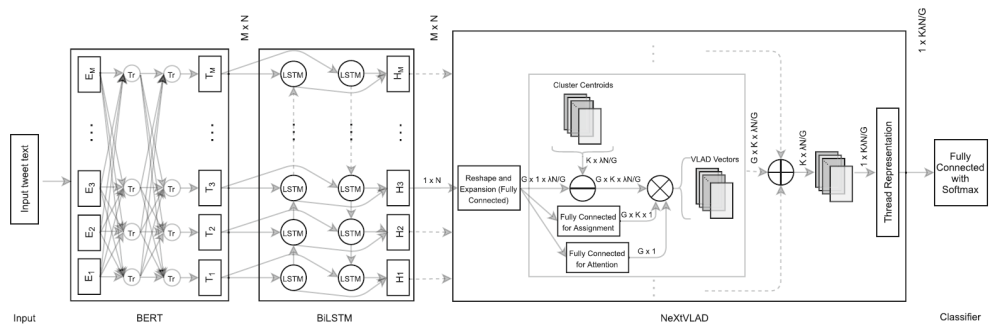
This approach suggests that Natural Language Processing (NLP) is the most promising method to fight fake texts, as it can detect them in real time before they can spread throughout social media. The model comprises BERT, Bidirectional LSTM for detecting temporal relations, efficient neural network NeXtVLAD, and Bag of Visual Words for data encoding.
- BotSSCL

BotSSCL stands for Bot detection with Self-Supervised Contrastive Learning. It employs contrastive learning, which separates human users from bots by analyzing four social account feature types: Metadata with unique statistics, Tweets represented as embeddings, Tweet Metadata including likes, comments and retweets, as well as Tweet Temporal that analyzes account’s behavior and posting frequency.
- SATAR
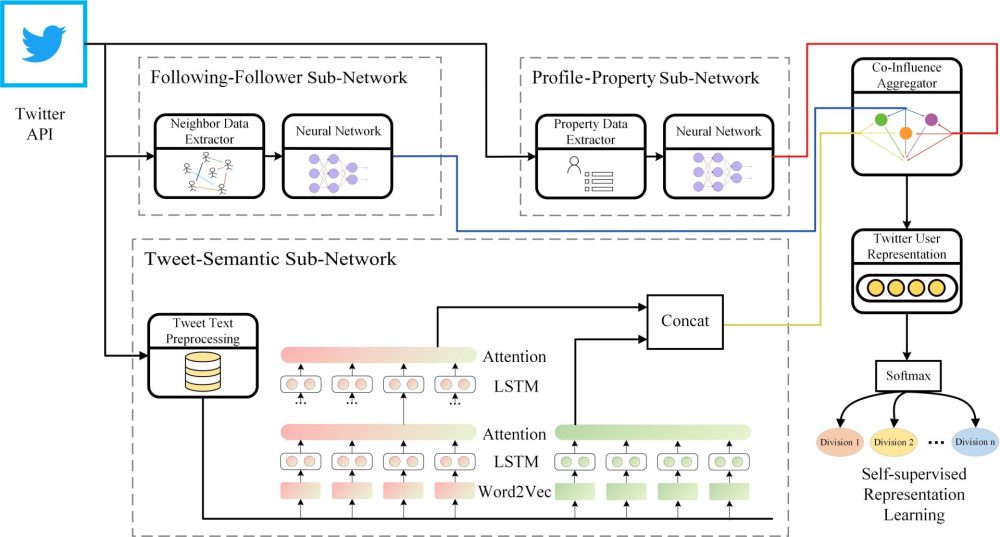
This method is based on a self-supervised representation learning framework. It’s capable of encoding tweet, property, and neighborhood information related to a user, while also using the follower count as the primary self-supervised signal for training. The model consists of four elements: 1) tweet-semantic subnetwork 2) profile-property subnetwork 3) following-follower subnetwork 4) co-influence aggregator.
- DeeProBot
DeeProBot focuses on the profile features of a user, namely its description. It employs pre-trained Global Vectors (GLoVe) to provide word representations, as well as long short-term memory (LSTM) with the addition of dense layers, so the model can process diverse input.
- Fusing BERT and Graph Convolutional Networks (GCN)
This combination of BERT and GCN produces a large, heterogeneous text graph. In turn, it allows for representing Twitter as nodes. This is achieved with the help of BERT representations and TF-IDF.
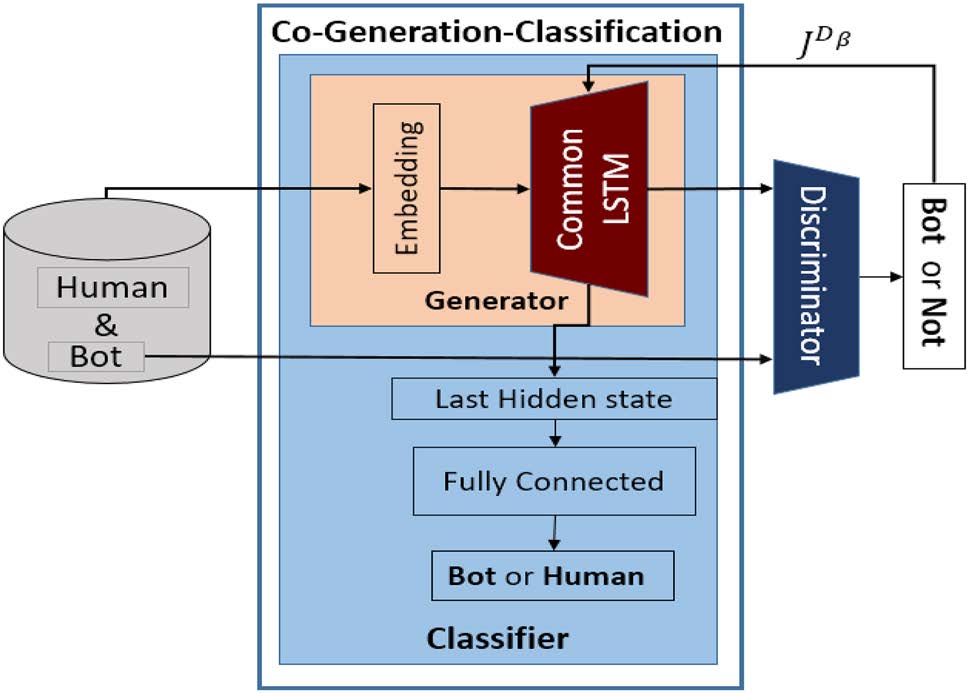
- GANBOT
GANBOT is based on the duo of a Generative Adversarial Network (GAN) and an LSTM layer that serves as an intermediary between generator and classifier.
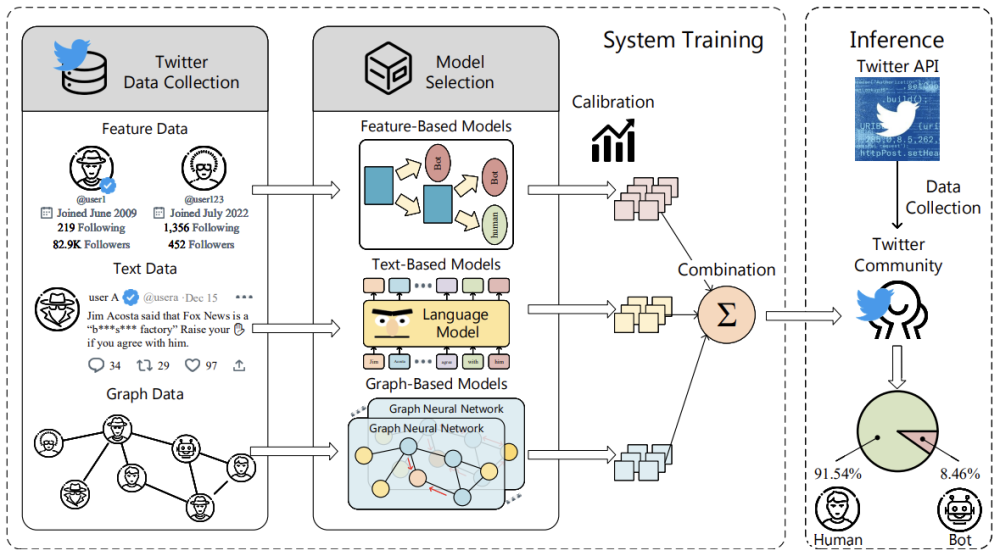
- BotPercent
BotPercent offers a collective approach to bot detection, as it focuses on entire communities where bots can be active, rather than individual cases. Its model absorbs multiple detection components, including those which are text-based, features, or graph-based.
Comparative Tests of Deepfake Tweet Detection Methods
An experiment tested various detection techniques on texts generated by GPT-2 and GPT-3: DistilBert, XLNet, BERTweet, and others were involved. While detection tools showed satisfying results at detecting GPT-2 content, their performance with the GPT-3 texts was much lower due to more humanized writing. However, authors note that GPT-3 content still displayed hidden features that signal their synthetic nature.
Trends and Challenges in Social Bots Detection
It is estimated that social media bots will evolve over time, adopting new tactics to stay undetected and produce harm. This includes camouflaging through emulating human behavior online, producing more diverse content, or exploiting weaknesses of the bot-detectors.
As suggested by experts, such countermeasures should be taken as incremental learning to detect dynamic fake content, parallel and distributed processing to make detection process scalable and cost-efficient, as well as data reduction, model distillation, and others.
Combating fake news requires a multi-pronged approach that goes beyond detecting generated text. Experts have suggested ways to detect deepfake images which could be used to spread fake news; among these techniques is digital watermarking. To read on about this proposed solution for deepfake detection, read our next article here.
 Antispoofing
Antispoofing



