

In the light of the rapid advancement of machine learning, issues regarding Intellectual Property (IP) have become especially relevant. In essence, there are three main concerns:
- Training. GenAI’s output — like that of ChatGPT — can be created only after it receives training on images, audio, computer code, and other creative sources made by someone else.
- Output. It is unclear who gets to own the copyright whenever GenAI is used to produce something, be it an orchestral score or a basic GIF-animation.
- Impersonation. Is it legally and morally acceptable to design AI’s work after someone’s unique artistic vision and style or a given person’s likeness or voice?
As a result, a number of thought experiments and concepts have been proposed to preserve Intellectual Property rights in the Generative AI era.
Examples of Copyright Violations in GenAI and Copyright Experiments
It’s been reported by IEEE Spectrum that Midjourney v6 produces pictures almost entirely identical to movie/cartoon footage if a prompt contains at least a slightly alluded hint to a scene in question.
A similar study aimed at Stable Diffusion v. 1.4 demonstrated that the diffusion architecture essentially copies and reconstructs an original picture with minor changes during the generation time. The initial training data was extracted with the help of a generate-and-filter pipeline, and the results demonstrated how vulnerable diffusion models can be in terms of privacy and trademark infringement. On the other hand, Generative Adversarial Network (GAN) models prove to be more plagiarism-immune as they are fed only indirect information about a training dataset.

It is suggested that fair use claims — a legal rule that allows using portions of a copyrighted material known as “verbatim” — may not be applicable to GenAI. As an illustration, a court case from 2015 Penguin Group (USA) Inc. v. American Buddha sued a non-profit organization since their library included four copyrighted books from the company’s catalog, as the changes applied by American Buddha to that literature didn’t meet the fair use requirements — the entire book contents were still available for free.
As a result, it is disputed that an AI cannot legally recite children’s literature word for word without violating IP rights. Led by that logic, AI presumably also cannot create video footage based on that literature, tell its story through illustrations, and so on. Besides, if tasked to create a similar original story, it will most probably “regurgitate” snippets of some initial training material, thus practicing partial plagiarism.

Applying Copyright to GenAI Products
Some legislative efforts have been made to resolve copyright issues.
North America
In Canada, an intellectual property should display originality as well as “exercise of skill and judgment.” That means that AI-based creation must be sufficiently modified by a human author to be considered original.
In the U.S., "sufficient creative control" is the main factor which determines whether a piece of material is copyrighted. In 2023, U.S. District Court Judge Beryl A. Howell ruled that a piece of art solely generated by an algorithm of the Creative Machine upon Stephen Thaler’s prompt cannot be copyrighted, as “human authorship is a bedrock requirement of copyright.”

Europe
In the U.K., the 1988 CDPA act states that anyone who arranged the conditions for a creative work to be accomplished should be considered its rightful author. However, it is not always clear who arranged these conditions — the user inserting a prompt, or the developer who designed the system? The AI cannot own the copyright since it is not human. Opinions divide from acknowledging both parties as the authors to claiming that AI-based works belong to the public domain.
India
In India it is argued that intellectual property can actually be copied and stored by a GenAI as long as the form of expression — the legally protected component of any intellectual work — is not publicly or privately exposed to anyone.
Fair Use and Copyright Issues While Training GenAI
A more adversarial point of view coming from the AI development community was expressed by American company Anthropic. The company, which was sued by a number of music publishers for infringement of the song lyrics, retorted with a statement that the lyrical content analysis was “a quintessentially lawful use of materials.” This would mean it falls under the fair use rules, as it does not exploit the expressive purpose and emotional component of the lyrics for financial gain.
Copyrightability of AI-Generated Content
As opposed to Stephen Thaler’s case, another GenAI-based work by Kris Kashtanova was recognized as Intellectual Property by the US Copyright Office. The short story was acknowledged to contain original text and arrangement of illustrations that conveyed the narrative. As for the images, however, they were considered non-copyrightable since no human has actually authored them.

Protection of Intellectual Property Rights Using GenAI: Experiments
Research has coined the term “Snoopy Problem,” named after the character Snoopy from the comic strip Peanuts. The term implies that a tightly copyrighted piece of work — akin to the Peanuts roster of characters — will be more likely copied by a GenAI than another less legally shielded image.
One of the approaches states that intellectual property could be protected with watermarks that are embedded through encoders. They will also be supported with decoders that in turn will retrieve watermarks, thus protecting intellectual property present in a dataset. Plus, an architecture attribution — which exposes a GenAI by its architectural characteristics — can help trace some unwanted content that violates IP rights.
Self-Regulation of GenAI Copyright Problem
One of the proposed methods to protect the IP rights and privacy is to make a GenAI model “unlearn” the copyrighted materials. This is possibly achievable through two stages: 1) Loss of information by the model with the help of contrastive labels 2) Stage output model retraining with knowledge distillation — a mechanism which transfers the gathered knowledge from a large model to a smaller one.
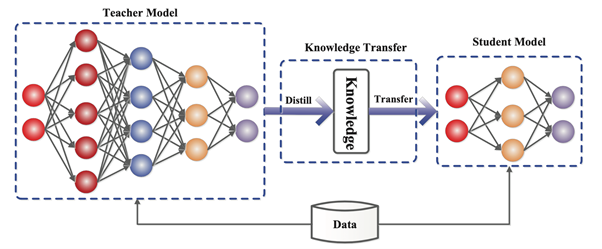
Another method suggests that AI developers should commit to creating legally and technically safe harbors that will prevent self-learning models from compromising private data, while also protecting developers from unwanted lawsuits.
GenAI Copyright Problem in Academic Writing

The Centre for Academic Integrity defines six main values for the academically involved: honesty, trust, fairness, respect, responsibility, and courage. However, the rise of GenAI may seriously sabotage these “moral pillars.” It paves the way for plagiarism, intellectual slacking, and other unscrupulous conduct. At the same time, it’s hard to overestimate the impact that AI has when it comes to the world of science. The only way forward is to somehow adapt GenAI to obey the mentioned six principles of academic integrity.
Possible Solutions and Frameworks
It has been suggested that a multi-pronged approach may help avoid violation of IP rights. It consists of:
- Data and output filtering that helps a model use only permitted data for training and help avoid replicating copyrighted works.
- instance attribution that identifies sources of the output.
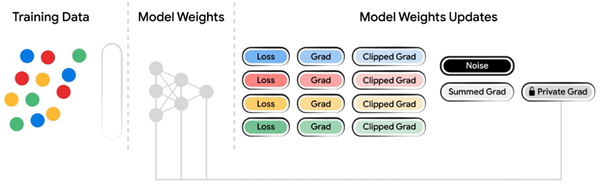
- Differentially private training that provides data anonymization.
- Fair use alignment via learning from human feedback that aligns the output with human values and inclinations.
This approach is intended to coordinate AI usage with fair use principles in the future.
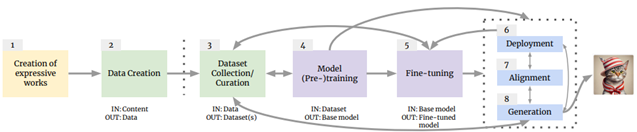
Generative-AI Supply Chain
Another study suggests using the GenAI supply chain — a framework that is capable of revealing when and by whom the copyright-related decisions were made regarding AI-based production.
Statutory Licensing
It is presumed that a statutory license could be introduced on a legislative level that will satisfy both parties: AI developers and rightsholders/creators. However, the remuneration should be reasonably limited to avoid unfair pricing.
Public Interest Theory
Public interest theory focuses on three main concepts: Preponderance, Common interest, and Unitary theories. In essence, these components dictate that the interest and benefits of the broad society should outweigh the interests of a select group, such as a corporation, government institution, and so on. Therefore, according to the Public Interest theory, copyright rules should be re-tailored in a way that avoids stymied technological progress, while also rewarding legitimate owners and authors for their work.
As Generative AI increases in usage and popularity, it’s unavoidable that it will eventually have an impact on the information available online — even scientific data. To learn more about the potential threats posed by use of Generative AI in scientific writing, read our next article here.
 Antispoofing
Antispoofing



