Definition and Problem Overview

With the introduction of ChatGPT in November 2022, significant concern has been raised around content created by Generative Artificial Intelligence (AI). The chatbot — the early version of which was designed in 2018 — is based on foundational and large language models (LLMs). Consequently, it can generate extensive bulks of text of various types, while also staying in tune with context and writing style.
However, ChatGPT also revealed some threats in regard to news, medical and scientific writing, as well as software development. Prominent universities including Oxford and Cambridge as well as a number of the US public schools, have banned its usage.
Researchers name the following threats related to AI-texts:
- Low accuracy. It is claimed that chatbots may provide misinformation, which can be especially harmful to medical research.
- Cognitive impact. Employing AI instead of one’s own expertise and ingenuity delivers a negative impact on creative skills.
- Bias. It is reported that ChatGPT can endorse sexist and, perhaps, other stereotypes. The jailbreak maneuver Do Anything Now or DAN, which received attention on Reddit, further aggravates the problem.
- Privacy threats. When generating answers, the chatbot leaks the private details of people engaged in the research that it’s using.
As a result, some methods are proposed to differentiate texts generated with AI from those written by human authors.

Natural Language Generation
To understand how an AI-text can be detected, it’s worth reviewing a technology that allows producing it. First, machine-generated text can successfully emulate natural language — e.g. the language that humans use to communicate and express themselves both orally or in writing. (Computer code is a non-natural language.)
The first Natural Language Generation (NLG) technique can be dated back to 1966 when Eliza — the earliest chatbot in history — was designed by Joseph Weizenbaum. It was based on two principles:
- Pattern matching that checked a certain string of tokens to detect if the constituents of some patterns were present in the conversation.
- Substitution methodology, which further allowed the bot to ‘develop’ a conversation, using a certain keyword as a starting point.
Modern NLG methods are divided into Neural and Non-neural approaches.

Neural approaches
NLG based on neural networks is separated into two classes: Non-transformer and Transformer methods.
Non-transformer methods rely on Recurrent Neural Networks (RNN), long short-term memory (LSTM), inverse reinforcement learning (IRL), and gated recurrent units (GRUs), as primary tools. However, their usage leads to vanishing gradient issue when a neural network’s weight is prevented from changing its value. As a result, this can completely halt training of an RNN or any other neural architecture.
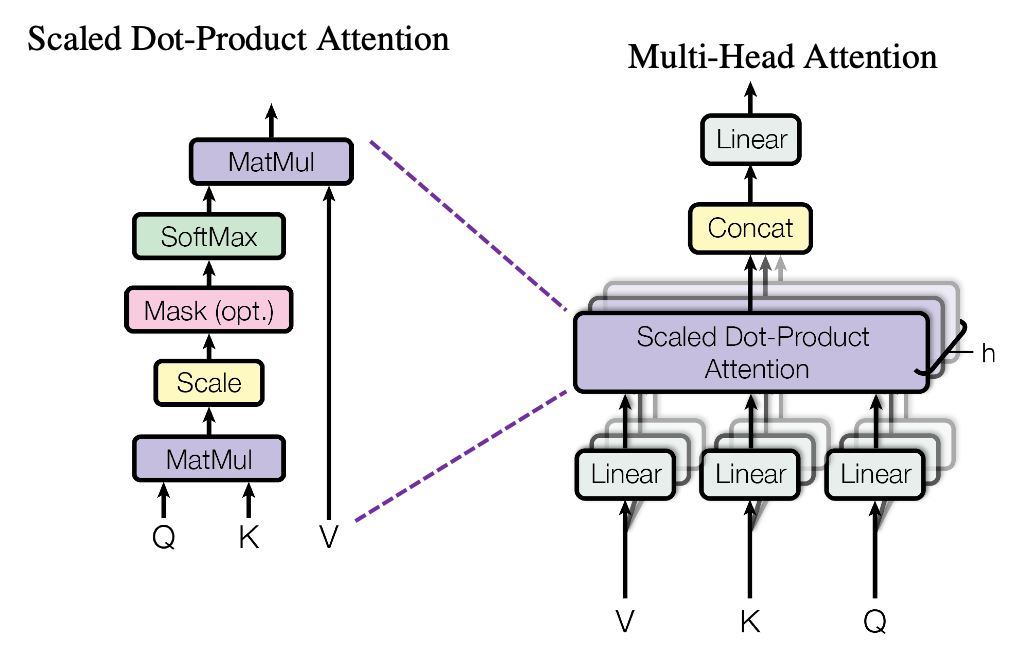
Transformer methods include models that rely on multi-head attention architecture. The ‘gimmick’ of such a mechanism is situated in its self-supervised distribution estimation that predicts the next token based on previous tokens, according to a study. GPT architectures are based on this technique too. Autoregressive language models, such as Google’s Transformer, GPT-J, and others also fall under this category.
Non-neural approaches
This class includes rule-based approaches implying they follow standard rules inherent in linguistics. They analyze a large natural language dataset to develop guidelines when forming content or composing templates later used in sentence construction. They rely on Hidden Markov Models (HMM), reinforcement learning, Markov Decision Process (MDP), and other techniques.
Generated Text Attacks
As highlighted, AI-generated texts can pose a serious threat to social, financial, cultural, and digital aspects of security. Among emphasized dangers are:
- Disinformation. An advanced text generator is capable of producing believable, yet fake headlines, articles, quotes, and other fraudulent info
- Impersonation. AI can plausibly imitate a person’s written language mirroring their specific word choice, punctuation, and other nuances. This threat is especially effective with hijacked emails.
- Scamming. It’s possible to orchestrate a virtually free scam attack targeting multiple people at once via chats with a text generator — something that scammers had to hire people for in the past.
- Model poisoning. From the technical point of view, AI-generated texts (including code) can be infused into training datasets to sabotage training of a neural network architecture, thus rendering antispoofing efforts fruitless.
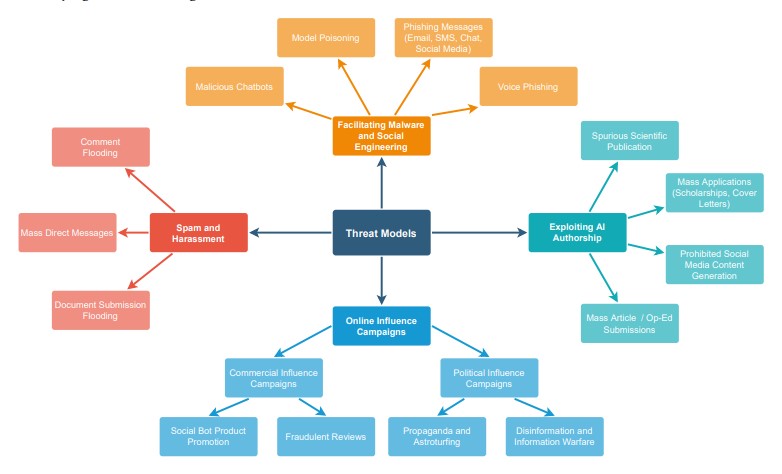
Moral issues cannot be discarded either, as text generators are often taught to endorse unethical behavior, utter racial or sexist slurs, perpetuate offensive stereotypes, threaten people, commit plagiarism, and so on.

Detection Frameworks and Online Tools
A constellation of tools has been developed to detect AI-generated texts — they employ a variety of techniques that analyze characteristics of the written language. Among them are stylometric signals, which help analyze stylistic properties of a text: Stylometric Detection of AI-generated Text.
OpenAI Text Classifier is a Generative Pre-trained Transformer (GPT) neural network that is trained to predict whether a text is artificial or not. GPTZero is a classification model that is trained to spot usage of a Large Language Model in a document. Writefull GPT Detector is mainly used for spotting plagiarism, but it’s also capable of recognizing AI-texts due to its percentage-based system.
Similar tools include Hugging Face, Copyleaks, Content at Scale, Draft and Goal, Originality.ai, and so forth.
Evaluation Metrics
The following metrics are proposed for evaluating AI-text detection:
- True Positive Rate (TPR). It measures the sensitivity of a detection model.
- True Positive (TP). The total amount of successfully detected AI-generated samples.
- False Negative. The amount of AI-generated samples that are undetected or misidentified as human writing.
- True Negative Rate (TNR). A number of correctly detected human-written samples.
All metrics are provided by this study.
Datasets, Detection Methods, Experiments
There are two major approaches in text detection based on feature analysis and Neural Language Models (NLMs).
Feature-based analysis
In feature-based analysis, success is directly influenced by the choice of language model sampling methods as they focus on different artifacts observed in an AI-generated text. The known techniques include frequency feature analysis, which utilizes Zipf’s law that states that the frequencies of certain words are inversely proportional to their ranks.
Fluency features allow measuring the general readability of a text: at some point it is expected that the coherency of a text written by an AI always diminishes. Linguistic Features from Auxiliary Models can detect the distribution of two types of tags: sample part-of-speech (POS) and named entity (NE) as bot and human writing greatly differ in regard to these values. Basic Text Features focus on punctuation, sentence length, etc.
Feature extraction can be performed with the help of the RoBERTa-Sentinel model.
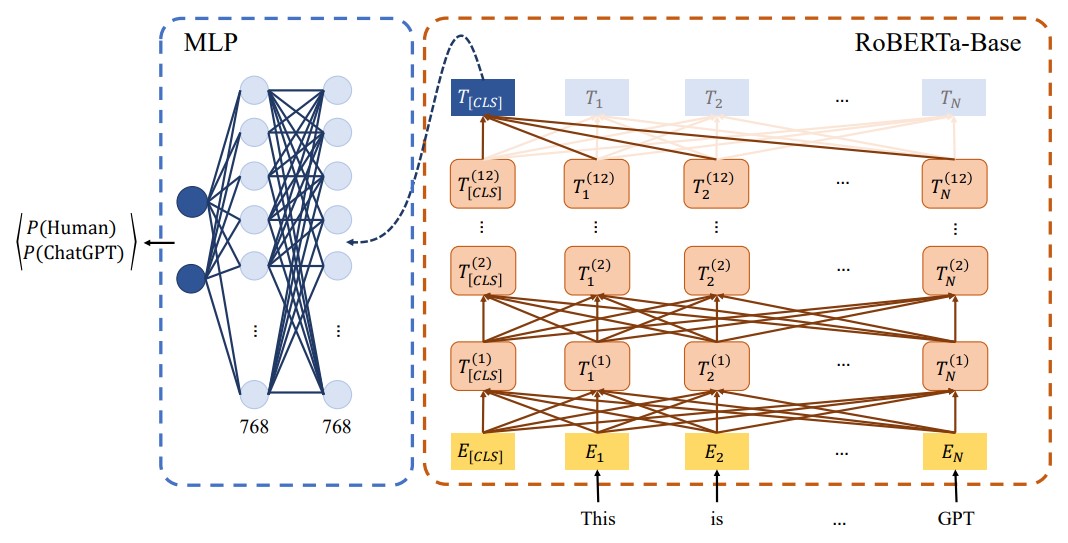
NLM analysis
It includes two methods:
Zero-shot method directly employs such unidirectional models as GPT to make them detect their own creation. It analyzes preceding and following tokens in a generated text and creates a token sequence with the help of a classification token. Eventually, the embedding tokens can be used as feature vectors for further analysis.
Fine-tuning method focuses on fine-tuning of large bidirectional language models. A masked general-purpose language model undergoes further fine-tuning to detect synthetic texts. An example of such a model is T5-Sentinel.
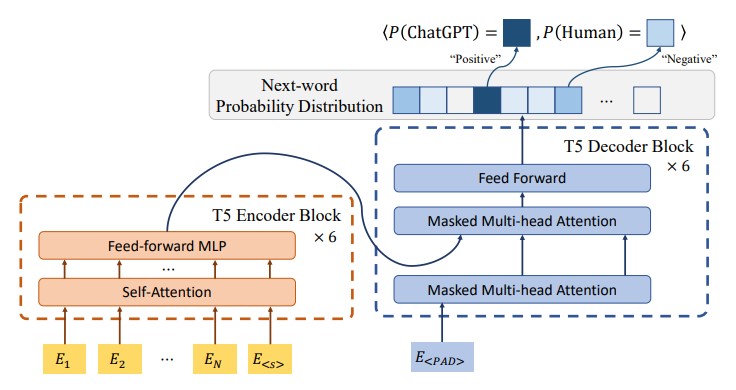
Datasets
OpenGPTText dataset comprises 29,395 text samples generated by the GPT-3.5-turbo language model. It was successfully used to test the RoBERTa-Sentinel model. The dataset dubbed OpenWebText comprises various text samples drawn from URLs posted on Reddit. And 130 extra datasets related to text generation can be found here.
Medical Texts Evaluation
It is stated that ChatGPT and other text generators are unable to write valuable medical texts as they lack depth, topic understanding, and general expertise that qualified human authors demonstrate. Another research has concluded that auto-generated texts cannot follow format requirements and are easily detectable by an AI output detector.
Manual Detection
While a ‘casual’ text generated by an AI is easily identifiable due to its rather unimaginative word choice and, at times, clumsy or stiff sentence structure, detecting a synthesized scientific text is difficult. It’s suggested to pay attention to:
- Punctuation.
- Paragraph complexity.
- Sentence length diversity.
- Use of popular ‘buzzwords’, such as terminology.
For instance, it is observed that human authors vary the sentence length more often, while AI-generated sentences stick to the same length more systematically. Besides, human authors tend to use proper nouns and specific punctuation, such as question marks, and also widely exploit special terms: et al., circa, etc.
References
- Joseph Weizenbaum is the forefather of artificial text generation
- Top French university bans use of ChatGPT to prevent plagiarism
- People Are Testing Chat GPT And Sharing Their Hilarious Results On Twitter
- Multi-head attention mechanism: "queries", "keys", and "values," over and over again
- ELIZA, From Wikipedia
- Machine Generated Text: A Comprehensive Survey of Threat Models and Detection Methods
- Nigerian Cyber Scammers
- GPT-Sentinel: Distinguishing Human and ChatGPT Generated Content
- A Short History Of ChatGPT: How We Got To Where We Are Today
- What Are Generative AI, Large Language Models, and Foundation Models?
- Which UK Universities have banned ChatGPT?
- These Schools and Colleges Have Banned Chat GPT and Similar AI Tools
- Opportunities and risks of ChatGPT in medicine, science, and academic publishing: a modern Promethean dilemma
- Differentiate ChatGPT-generated and Human-written Medical Texts
- DAN (Do Anything Now)
- Extracting Training Data from Large Language Models
- Natural language, From Wikipedia
- How the first chatbot predicted the dangers of AI more than 50 years ago
- Vanishing Gradient Problem: Causes, Consequences, and Solutions
- MGTBench: Benchmarking Machine-Generated Text Detection
- Attention Is All You Need
- GPT-J
- Rule Based Approach in NLP
- Stylometric Detection of AI-Generated Text in Twitter Timelines
- New AI classifier for indicating AI-written text
- GPTZero. The Global Standard for AI Detection
- See if a text comes from GPT-3, GPT-4 or ChatGPT
- The AI community building the future
- AI-based text analysis to help create and protect original content
- Publish high-ranking content…instantly
- ChatGPT - GPT3 Content Detector
- Most Accurate AI Content Detector & Plagiarism Checker for Content Marketers
- To ChatGPT, or not to ChatGPT: That is the question!
- Zipf’s Law
- Dataset Card for "openwebtext"
- Machine Learning Datasets
- Distinguishing academic science writing from humans or ChatGPT with over 99% accuracy using off-the-shelf machine learning tools
- Comparing scientific abstracts generated by ChatGPT to original abstracts using an artificial intelligence output detector, plagiarism detector, and blinded human reviewers
 Antispoofing
Antispoofing