Problem Overview and Certification
In liveness taxonomy, Adversarial Spoofing Attacks (AXs) refer to a technique which uses spoofed data presented to the authentication system as genuine material. This type of malicious attack exploits the lack of robustness in a Deep Neural Network (DNN), which is responsible for the correct response and decision-making of a biometric solution. The Adversarial Spoofing Attack tools are called “adversarial examples.”

AXs should not be confused with Presentation Attacks (PAs) as they don't involve forged biometric traits — though they may pursue biometric spoofing in some cases. Instead, fraudsters employ input data with added noises (“perturbations”) which leads to instability in a DNN's work. Visual recognition models are the top targets in this scenario, although voice or text recognition solutions are also at risk.
Since AXs jeopardize safety-critical systems — like autonomous cars or runway alignment used in aviation — it is of vital importance to assess their robustness. DNN certification is challenging due to their black box architecture, complexity, large size, and so on.
Such a certification aims to examine the lower bound of a DNN's robustness when it faces an adversarial spoofing attack. As of now a few methods are offered to attest DNNs: DeepTest, SoK, Reluplex, and others.

Threat Model of Adversarial Spoofing Attack
AXs have the goal of causing a misclassification, using perturbations added to an input data. The phenomenon itself was first observed in 2014 in a paper by Szegedy et al. However, methods to achieve that misclassification may vary. We’ll discuss a few of the different models and mention a number of adversarial techniques.
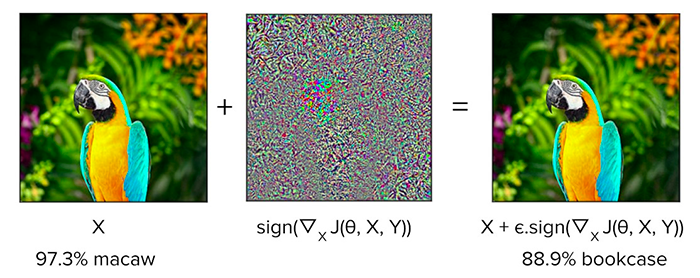
One type of attack employs the Fast Gradient Sign Method (FGSM) described by Goodfellow et al. This attack technique includes making a prediction on the image with a Convolutional Neural Network (CNN), calculating its loss with the true class label, estimating the gradient loss and sign, and other steps.
The Carlini-Wagner model proposes a minimal perturbation usage, which is possible due to optimization problem-solving. The authors review seven objective functions, while also pointing out that a loss function proposed by Szegedy et al. isn't effective due to its complexity and high non-linearity. Instead, they offer the most efficient objective function:
[math]\displaystyle{ f(x^t)=\max(\max\{Z(x^t)i : i \neq t\} - Z(x^t)t,-k) }[/math]
- [math]\displaystyle{ Z(x^t) }[/math] — probability vector.
- [math]\displaystyle{ \max\{Z(x^t)i : i \neq t\} }[/math] — non-target class highest probability.
- [math]\displaystyle{ \max\{Z(x^t)i : i \neq t\} - Z(x^t) }[/math] — difference between the actual visual data and a probable misidentified object.
Based on this objective function, it's possible to fashion a high-confidence adversarial spoofing attack.

An alternative model proposed by Rozsa et al. focuses on internal layer representation alignment with the target image. This technique allows the production of AXs and manipulating the feature representation, which is extracted by the DNNs for facial verification, among all else.
Types of Adversarial Attacks
AXs are separated into three categories: evasion, poisoning, and exploratory.
Evasion attacks
Evasion attacks are a widespread type in which a malicious actor attempts to avoid a biometric system by adjusting the spoofed samples at the testing stage.
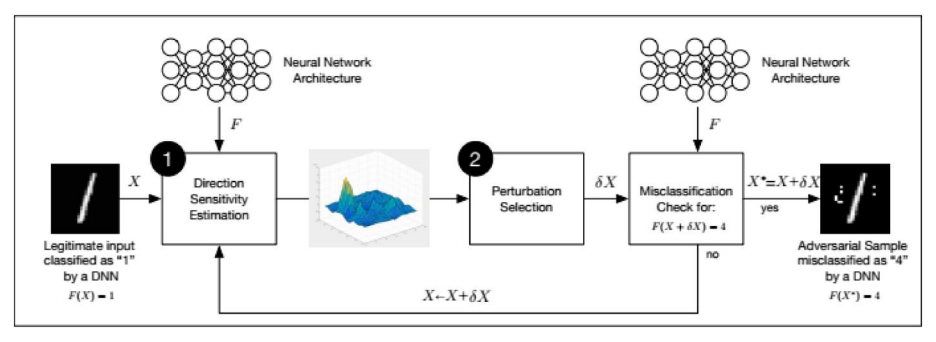
Poisoning attacks
This type is designed to infect (poison) the genuine training data with the adversarial examples. It is produced during the training stage with the goal of either decreasing its accuracy or completely sabotaging the liveness detection capability of a deep learning solution.

Exploratory attacks
This final type is even more insidious in nature. It seeks to expose the training algorithms of a biometric solution, as well as explore its training datasets. Then, based on the obtained knowledge, adversarial samples of high quality can be crafted.

Review of the Most Well-known Adversarial Spoofing Attacks
Along with the above-mentioned FGSM and Carlini-Wagner attacks, experts mention some other noteworthy AXs types. One of them, Jacobian-based Saliency Map Attack (JSMA) is a minimalistic technique, which allows altering only a few pixels in the visual data to spoof a system.
A similar approach is dubbed the “one pixel attack.” It includes a lengthy process of creating a number of [math]\displaystyle{ R^5 }[/math] vectors with [math]\displaystyle{ xy }[/math]-coordinates and RGB values and random modification of their elements to breed “parents-children,” which will eventually allow for creating the most fit pixel candidate.
The DeepFool method allows architecting a minimal norm of adversarial perturbation. This is possible due to region boundary linearization, perturbation accumulation, and other techniques. It is reported to be more effective than FGSM.
The Basic Iterative Method and the Least-Likely-Class Iterative Method (BIM and ILCM, respectively) are based on a simple concept of one-step increase of the loss of the classifier, which is repeated in multiple iterative smaller steps. At the same time, whenever a step is made, the direction of the model gets adjusted.
Expectation Over Transformation (EOT) is a peculiar method which employs texture, camera distance, lighting, pose, and solid-color background manipulations. This know-how is known as "distribution of image/object transformations".

Main Directions in Defense Against Adversarial Spoofing Attacks
Now that we know how adversarial attacks are trained and deployed, let’s explore some of the tactics to prevent them. Three main approaches are suggested to prevent AXs.
Modified Training/Input
Techniques in this vein include the following:
- Brute-force adversarial training with strong attacks.
- Data compression as defense with JPG compression on the FGSM-based perturbations.
- Foveation-based defense that applies a DNN to various image regions.
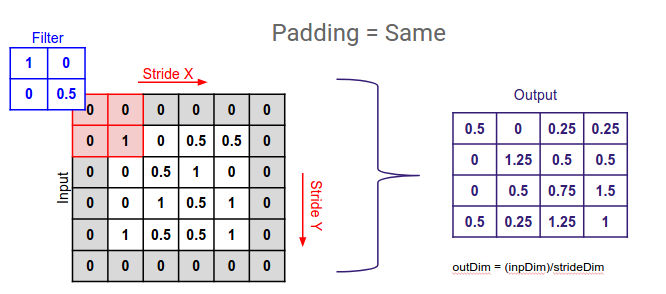
- Data randomization, which implies that attacks decrease in efficacy if random resizing and padding — addition of a number of pixels to an image — are applied to the adversarial examples.
Gaussian data augmentation is another potentially promising preventive measure.
Modifying the Network
This group of techniques involves:
- Deep Contractive Networks with the smoothness penalty applied to them during training.
- Gradient regularization featuring penalization of the degree of variation occurring in DNNs.
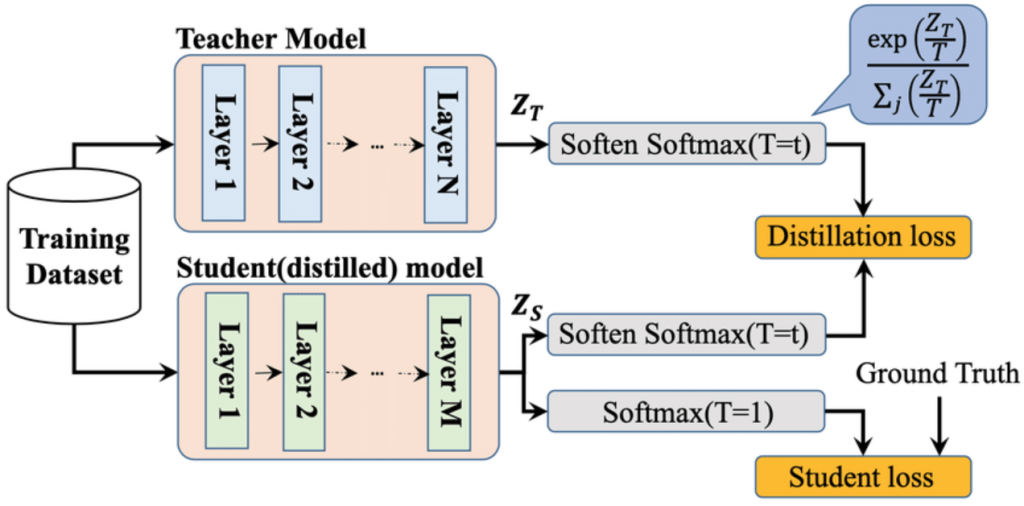
- Defensive distillation, implying knowledge transfer between bigger and smaller networks.
- Biologically-inspired protection enhances a system with highly non-linear activations.
- Parseval Networks introduce layer-wise regularization through the network's global Lipschitz constant regulation.
- DeepCloak offers inserting a masking layer before a classification layer.
Other know-hows include bounded ReLU, statistical filtering, output layer modification, additive noise usage, etc.
Network Add-ons
Preventative measures involving network add-ons include:
- Defense against universal perturbations with appending extra pre-input layers.
- GAN-based defense with the training process overseen by a Generative Adversarial Network.
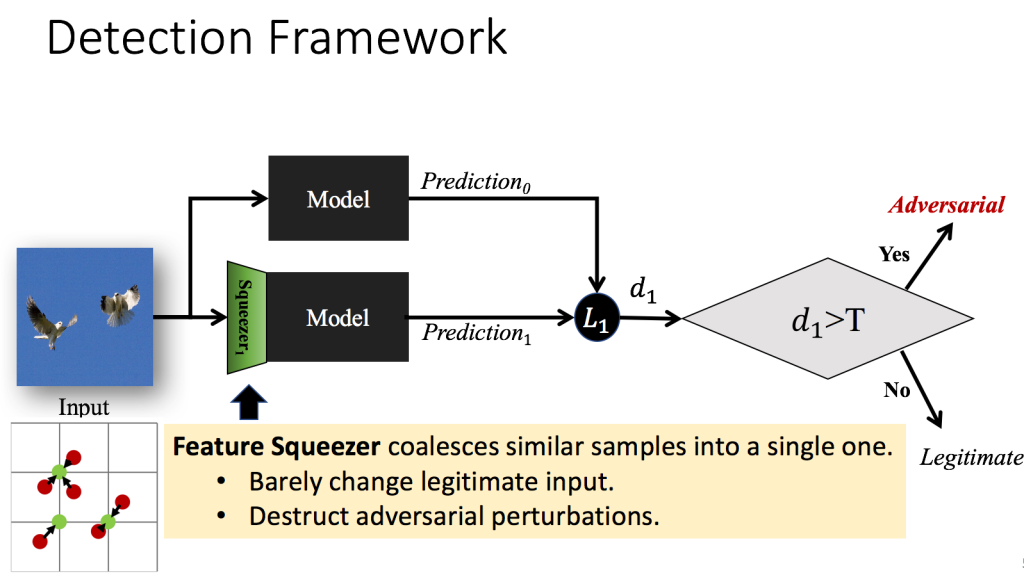
- Detection Only methods that include feature squeezing, external detectors, etc.
Other solutions include scalar quantization and spatial smoothing, persistent homology application, and so on.
Countermeasures Against Adversarial Spoofing Attacks
There are some additional tactics that can be useful in preventing adversarial attacks:
- Gradient hiding. This suggests that the gradient information should be hidden from the potential attackers.
- Blocked transferability. The DNN's transferability causes different classifiers to 'repeat' each other's mistakes, hence it must be blocked.
- MagNet. This uses a classifier as a black box, but avoids modifying it. Instead, detectors differentiate bona fide and adversarial samples.
High‐Level Representation Guided Denoiser (HGD) is also a promising tool, as it's capable of noise removal from the images in question with a loss function.
Competitions
There are at least two contests dedicated to addressing the problem of adversarial attacks: the Adversarial Attacks and Defenses Competition with two datasets DEV and FINAL, and the NIPS 2017 Adversarial Learning Competition.

Adversarial Spoofing in Voice Biometrics
Automatic Speaker Verification systems (ASV), especially as part of Remote Identity Proofing, are also vulnerable to AXs. To prevent these vulnerabilities, a Generative Adversarial Network for Biometric Anti-Spoofing (GANBA) was developed. Its architecture allows generating attacks, while also strengthening the discriminator responsible for Presentation Attack Detection (PAD).
GANBA, separated into White and Black box models, employs short-time Fourier transform features, Mel-frequency cepstral coefficients, Time Delay Neural Network (TDNN), and other components.
Adversarial Attacks in Natural Language Processing
As for Natural Language Processing (NLP), its DNN models, like Seq2Seq or Recurrent Neural Network (RNN), can also be spoofed with perturbations created with the likes of forward derivatives. They target various components, from Optical Character Recognition (OCR) to Visual-Semantic Embeddings (VSE). The proposed defense measures include adversarial training, model regularization, etc.

Other Instances of Adversarial Spoofing
AXs are also reported to be targeting object recognition, which is often used in anti-spoofing for IoT, video authentication, automatic spam and malware filtering, reinforced learning, and so on.
FAQ
Which spoofing attack types exist?
Spoofing attacks have varying types, with liveness spoofing being one of them.
Spoofing attacks focus on every aspect of digital space: emails, GPS, Caller ID, and so on. Liveness spoofing is relatively new, since it is much more elaborate than other spoofing attacks. Liveness spoofing includes replay and presentation attacks. The attack types have subtle differences between them.
Replay attacks involve a pre-recorded video or audio that is played to trick the biometric system. Presentation attacks imply that a spoofing item such as a photo, mask, fake fingerprint or artificial retina, is directly presented to the system's sensors. Modern liveness spoofing attacks have evolved to target every biometric parameter: appearance, voice, and so on. For more information about how presentation attacks work, read on in this next article.
References
- Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey
- How Neural Networks are Already Showing Future Potential for Aerospace
- Intriguing properties of neural networks
- Universal Adversarial Spoofing Attacks against Face Recognition
- Explaining and Harnessing Adversarial Examples
- Adversarial attacks with FGSM (Fast Gradient Sign Method)
- Towards Evaluating the Robustness of Neural Networks
- LOTS about Attacking Deep Features
- Remote sensing by Wikipedia
- Region-Wise Deep Feature Representation for Remote Sensing Images
- A survey on adversarial attacks and defences
- Illustration of exploratory attacks on a machine learning based spam filtering system
- Probabilistic Jacobian-based Saliency Maps Attacks
- Artificial Intelligence-Powered Systems and Applications in Wireless Networks
- Synthesizing Robust Adversarial Examples
- Padding (Machine Learning)
- Smoothness constraints in Deep Learning
- Defensive distillation scheme
- Detecting Adversarial Examples in Deep Neural Networks
- Persistent homology
- NDSS- Feature Squeezing Mitigates and Detects Carlini-Wagner Adversarial Examples
- Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser
- Adversarial Attacks and Defences Competition
- NIPS17 Adversarial learning - Final results
- DeepTest: Automated Testing of Deep-Neural-Network-driven Autonomous Cars
- GANBA: Generative Adversarial Network for Biometric Anti-Spoofing
- Attacking Natural Language Processing Systems With Adversarial Examples
- Adversarial Attacks and Defenses in Images, Graphs and Text: A Review
 Antispoofing
Antispoofing