
What Is Training Data Extraction Attack?

Data extraction attack is a technique that allows to obtain samples initially used for training a neural network. It is achievable by preparing a specific attack model that can infer if a certain data point was actually used in a training dataset.
What Makes Extracting Data Possible
Extraction attacks are possible due to the unintended memorization — a phenomenon when a Large Language Model (LLM) stores irrelevant data in its memory. This “side effect” is inevitable as the goal of the training process is to maximize the overall likelihood of the training dataset.
As a result, an LLM can display eidetic memorization when it retains small bits of data that appear in a dataset sporadically. However, this information can contain sensitive details, namely people’s addresses, SSN, phone numbers, and so on. Eventually, it can result in leakages with sensitive data getting compromised.
Experiments and Examples of Training Data Extraction Attacks
There are several experiments dedicated to the possible data extraction scenarios:
- Training Data Extraction Attacks on GPT-2
An experimental attack on GPT-2 showed that an LLM can remember verbatim data just after a few training epochs. To succeed, authors employed the membership inference attack with the help of a large set of synthesized text queries based on unconditional sampling.
- Training Data Extraction Attacks on GPT-3 and GPT-4

A divergence attack is a technique, in which a repeated single token is used to make the target GPT-3.5 model return to a lower-level language modeling objective. In turn, this reveals non-trivial stretches of the training data pieces stored in its memory.
- Training Data Extraction Attacks on ChatGPT

This method is also based on the previous divergence-approach. It’s used to make the LLM break the “confinement” of the alignment training that prevents leakage. The divergence attack makes the model “glitch” and revert to its pre-training data, bits of which it’ll insert in the output.
- Training Data Extraction Attacks on LLaMA and Falcon
Semi-closed models — like LLaMA and others — are trained on the datasets that aren’t openly known. To produce data extraction, an auxiliary dataset was built based on the Internet’s written content. Then, output of the target model is compared to this dataset — any successful matches serve as a clue that detected info was used for training purposes.
- Training Data Extraction Attacks on Pythia and GPT-Neo
Open-source models are the easiest to extract memorized data from, as their training datasets are publicly available. It’s possible to generate an enormous number of prompts and then compare a model’s output directly to its training data to identify the exact corpora.
- Training Data Extraction Attacks of Large Language Models Trained with Federated Learning Algorithms
It is discussed that it’s possible to orchestrate data extraction within the limits of federated learning (FL), which is used to defend private data. An attacker may use MG-FSM — a general-purpose frequent sequence algorithm for obtaining sequential data — to identify Frequent Word Sequences (FWS). As a result, it can help reveal a frequent prefix set that can help retrieve hidden information.
Countermeasures against Training Data Extraction Attacks
The Following methods are proposed to prevent data extraction:
- General Countermeasures against Training Data Extraction Attacks
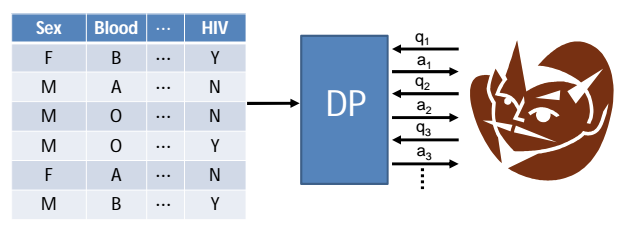
To shield the private data it is recommended to use Differential Privacy Training that employs differentially private stochastic gradient descent, curating, censoring and deduplicating training data, as well as keeping memorization limited with additional fine-tuning.
- Data Deduplication
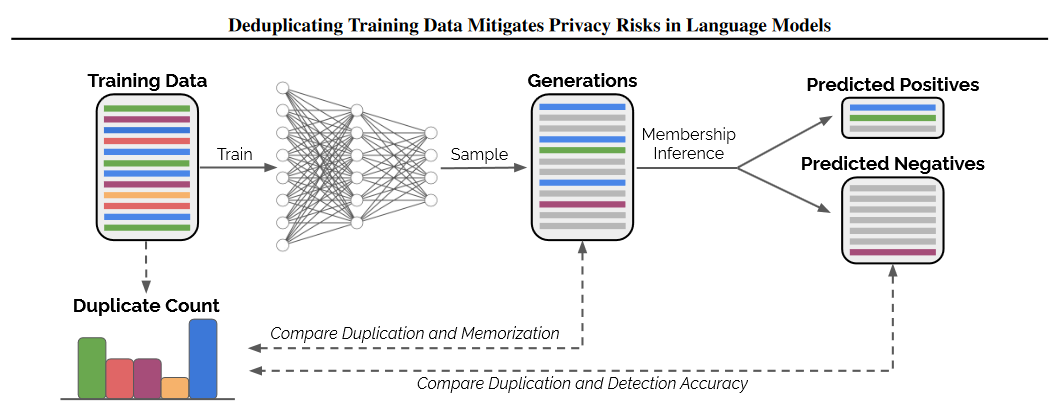
Basically all LLMs repeatedly duplicate training sequences — non-duplicate ones are barely featured in the regeneration process. Removing duplicate copies greatly mitigates the data mining risk through such methods as membership inference attack.
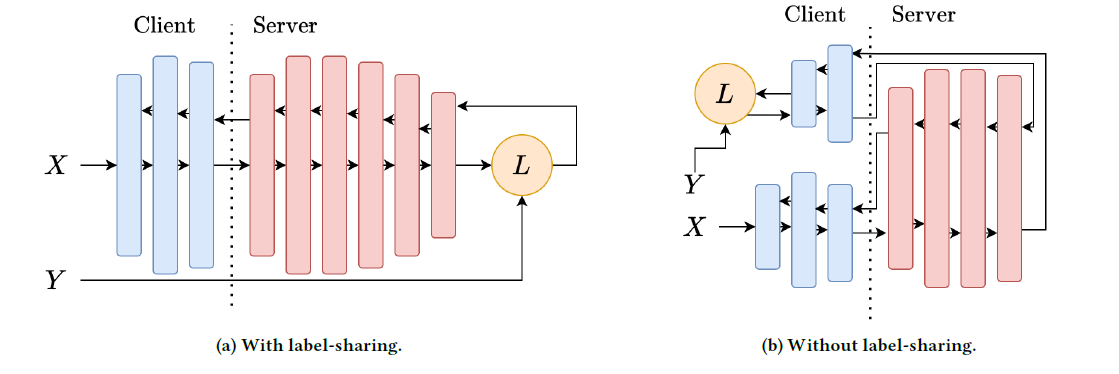
- Split Learning and Differential Privacy
Split learning refers to a technique when a neural network’s layer computation is split between the network’s clients and the server. Differential privacy is an algorithm that supplies data to a dataset without mentioning any personal attributions. Together they can nullify successful extraction attacks.
 Antispoofing
Antispoofing



