
What Is Membership Inference Attack?
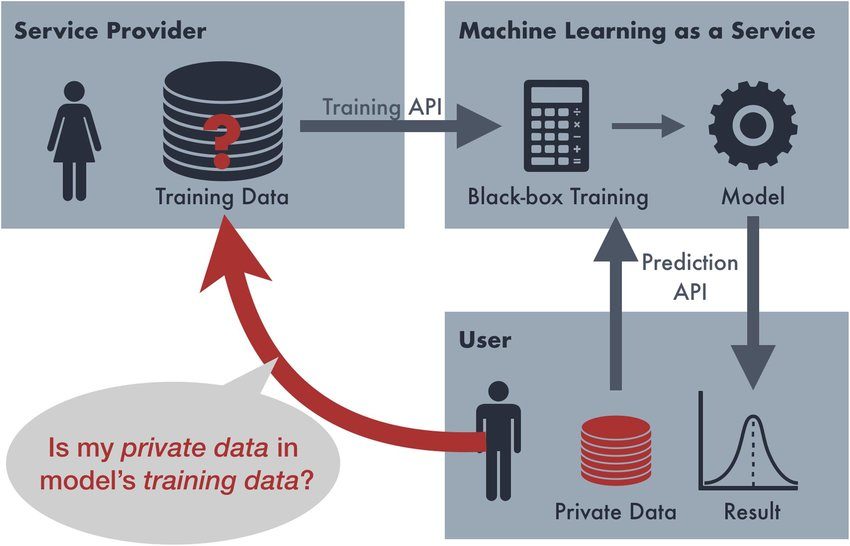
Membership Inference Attack (MIA) is a technique that reveals if a certain data sample was used for training a deep-learning model. Generative models, apart from classifying samples, should also be able to extend their performance to handle other, previously unseen data.
However, handling new and poorly explored data can somewhat decrease the model’s efficiency — this is a weakness point that adversaries can exploit with the help of MIAs.
Attack Model and Strategies
An attack model in the context of MIA typically comprises the following parameters:
- Environment
It refers to the knowledge level about the target model that an attacker has. There are three scenarios: Black-Box when nothing is known except general knowledge and the model’s output, Grey-Box when some data like distribution of features is known, and White-Box when everything, including the training data, is available.
- Shadow dataset
This implies a collection of data that mimics the original training dataset and isn’t authorized by an official developing team. It’s used to leverage the API.

- API investigation
At this stage critical info about API is retrieved through probing: number of features, classes, and so on.
- Generation of shadow samples
They are produced with the Statistics-, Active Learning-, Query-, and Region-Based Generation.
- Creation of the attack model
The attack model will be based on a dataset built upon the previously gathered shadow data. The model itself will play the role of a binary classifier that uses probability vector outputs to infer if the input samples were or were not used in the training phase.
Some Special Cases of Membership Inference Attacks
There’s a constellation of attack scenarios, in which MIAs can be featured:
- Likelihood Ratio Attack
Likelihood ratio attack (LRA) is based on statistical data and prediction that accepts or discards the notion that a sample was involved in the target model’s training. To make a prediction, it employs such factors as confidence scores and also trains shadow models.
- Membership Inference Attacks Against In-Context Learning
In this scenario, In-Context Learning is treated like a weakness, as it allows a model to memorize its recent answers and conversations. A hybrid attack can be utilized, including GAP attack, as well as Inquiry that asks if a model knows certain word sequences, Repeat, and Brainwash that misleads it with incorrect knowledge.

- Membership Inference Attacks Against Synthetic Health Data
An experiment showed that electronic medical records are vulnerable to inference attacks. These records may have unique features that do not recur throughout the set. They are dubbed “signatures” and stay irrelevant to the main data, which makes their accidental replication and consequent leakage possible.
- Similarity Distribution Based Membership Inference Attack

This technique employs the inter-sample similarity distribution — it helps detect conditional distribution of the similarity that target samples and other reference data may possibly share. It serves as a basis for a successful MIA.
- Subpopulation-Based Membership Inference Attack

The proposed method is claimed to be more practical in nature as it focuses on an entire subpopulation rather than on a single sample. Besides, it can detect if actual user data was brought up at the training stage and doesn't require numerous shadow models .
- User-Level Membership Inference Attack
The previous approach can also help extract user-data with the metric embedding learning — It finds a way to transform a high-dimensional input into a lower-dimensional latent space, where similar inputs get close to each other.

- Data Augmentation-Based Membership Inference Attacks
A technique based on semi-supervised learning (SSL) is proposed with additional data augmentation-based MIAs — a big part in this solution belongs to weakly/strongly augmented views, on which prediction agreement is trained.
- Membership Inference Attack on Diffusion Models
To extract training samples from a diffusion model, it is suggested to employ a learned quantile regression model that is able to predict reconstruction loss distribution for every piece of data.
Countermeasures and Defense against Membership Inference Attacks
To avoid MIAs it is recommended to employ regularization that tackles overfitting in neural models, use differential privacy algorithms, restricting the prediction vector and increasing its entropy, prompt-based defence with safety instructions given to the model, and so on.
 Antispoofing
Antispoofing



