
EfficientNet: Brief Overview
Convolutional neural networks (CNNs) were first introduced in the 1980s. One of the first known examples of CNN was the Time Delay Neural Network (TDNN) developed in 1987 by Alex Waibel and his research team. TDNN was focused on speech recognition, including shift-invariant phoneme recognition. The first work on modern convolutional neural networks (CNNs) occurred in the 1990s when a paper bby Yann LeCun et al. titled “Gradient-Based Learning Applied to Document Recognition” was published. Later, the architecture was adapted for deepfake detection.

CNN architecture has since kept on evolving. EfficientNet was proposed in 2019 in a study, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. While being a novel method, EfficientNet also suggested a revolutionary technique of boosting performance of CNNs, which are quite often used for detecting facial deepfakes.
Typically, a steadfast resource cost is invested when building a CNN. Afterwards, it is possible to scale up such a neural network to achieve a higher performance accuracy if additional resources are used. This may include increasing the number of layers used in a CNN, and so on.

However, the traditional model scaling may prove ineffective. Increasing even a single dimension of a CNN enhances the accuracy of a neural network. At the same time, traditional methods require a lot of manual fine-tuning, while sometimes providing trifling results at best.
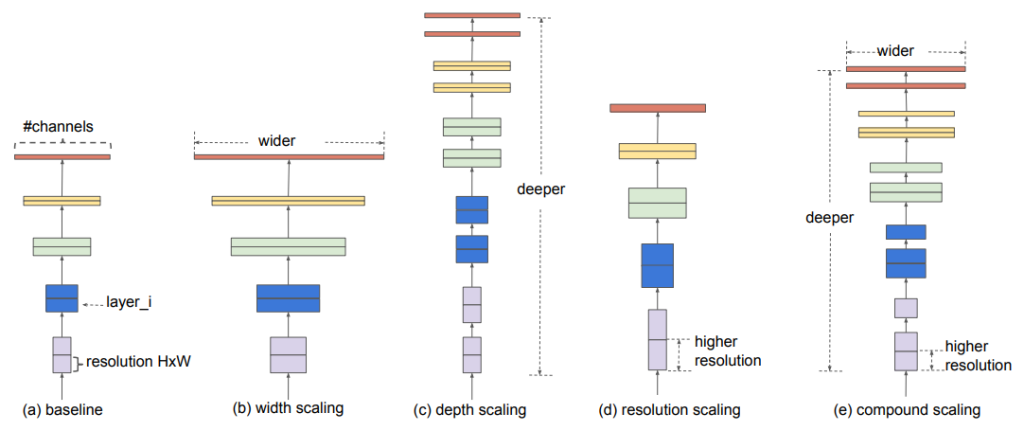
EfficientNet aspires to solve this issue. Its architecture implies that all dimensions of a CNN — like width, depth, and resolution — will be scaled up evenly. This is possible thanks to the compound coefficient, which guarantees a more structured approach.
With a fixed set of scaling coefficients, EfficientNet is capable of achieving impressive results. It's reported efficiency can be as high as 10x better compared to other methods.
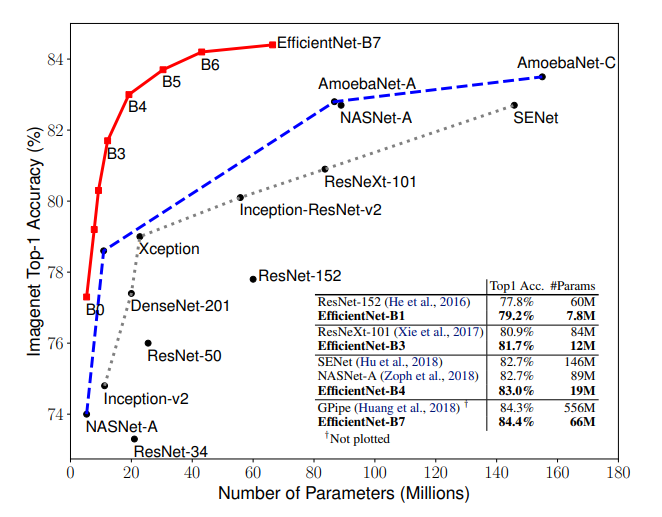
As reported, EfficientNet-B7 works 6.1x faster, while being 8.4x smaller than other existing CNNs. Its ImageNet accuracy rate is estimated as state-of-the-art 84.3%. EfficientNet’s CIFAR-100 accuracy is reported to be 91.7%.
EfficientNet Architecture: Specifications & Technicalities
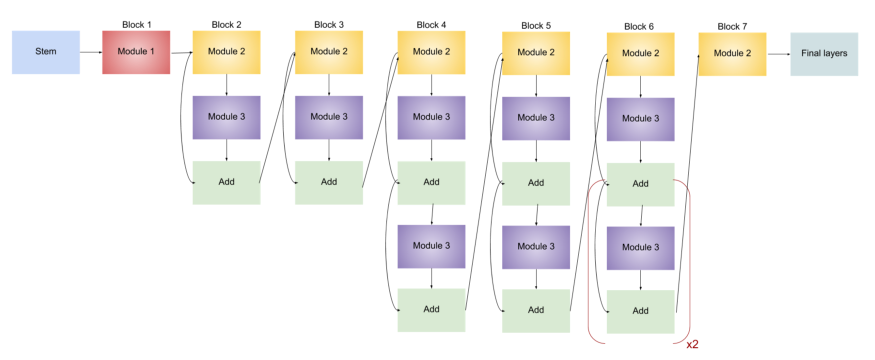
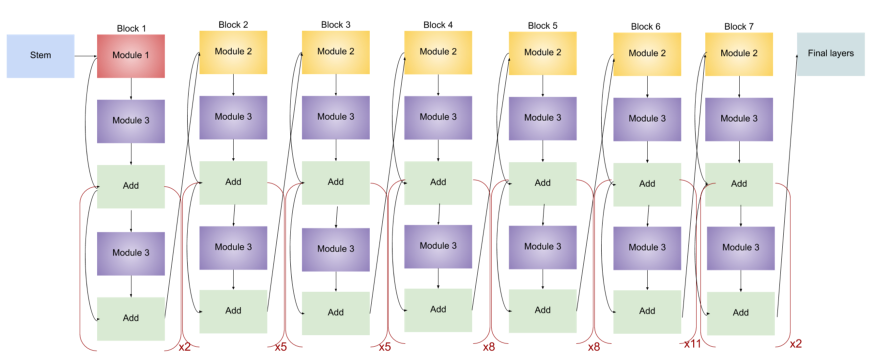
In essence, EfficientNet’s architecture is not too complicated. Baseline network Efficientnet-B0 plays a role of a groundwork or stem for further scaling. Authors highlight that they used a Neural Architecture Search (NAS) to construct it, which is a reinforcement learning-based method.
With its help, the multi-objective search was leveraged — this allows optimized accuracy of the network, as well as FLOPS.
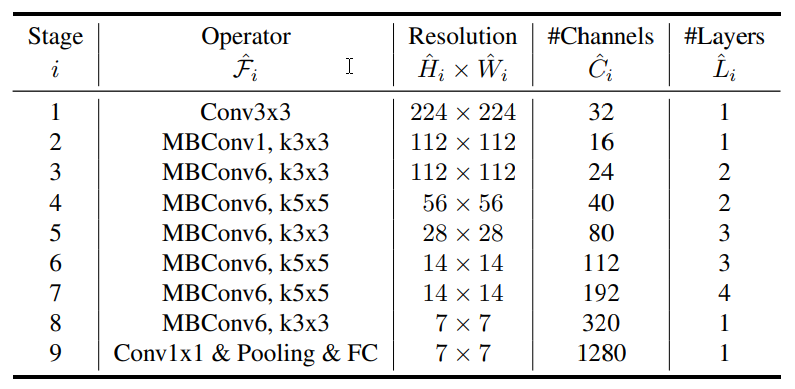
EfficientNet includes 8 models: from B0 to B7. Each of them has 7 blocks that are reinforced with a varying number of sub-blocks. As the system upgrades from B0 to B7, the sub-block quantity grows.
Moreover, EfficientNet-B0 employs an inverted bottleneck with Depthwise Convolution operation. This bottleneck design implies usage of 1x1 convolution, which brings down the channel number. It was first introduced as part of the CNN dubbed InceptionV2.
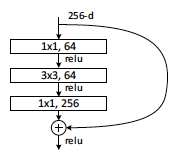
Then, 3x3 and 5x5 convolution operations are applied to receive output features from the decreased number of channels. Lastly, a 1x1 convolution procedure is applied again to "dial" the channel quantity back to the initial number.
However, in the case of EfficientNet, this procedure is reversed. Bottleneck inversion does not reduce the channel number. Instead, their number is tripled by the first 1x1 convolutional layer.

Next, EfficientNet employs 5 modules that serve as a groundwork for building layers of the neural network.
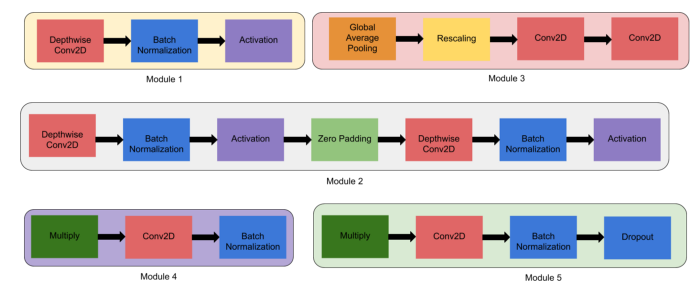
- Module 1. This forms the basis for the sub-blocks.
- Module 2. A foundation for the first sub-block on which 7 main blocks are based (except for the 0 block).
- Module 3. It is connected to the network’s sub-blocks as skip connection.
- Module 4. Employed for combining the skip connection in the first sub-blocks.
- Module 5. It combines sub-blocks as a whole through skip connection, while every sub-block is connected to the preceding sub-block.
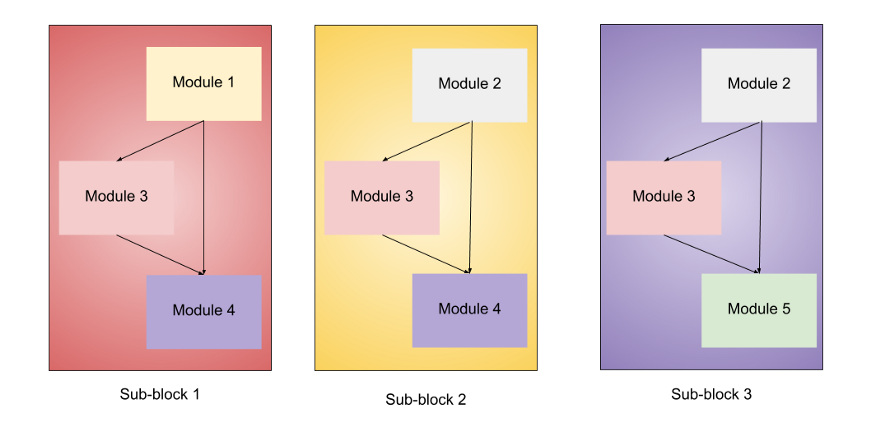
Eventually, all modules are incorporated to form 3 sub-blocks for specific purposes.
- Sub-block #1. It’s used as the first sub-block in the first block.
- Sub-block #2. Serves as the first sub-block in all other blocks.
- Sub-block #3. Used for all sub-blocks except every first sub-block in all blocks.
Naturally, EfficientNet architecture becomes more elaborate with each model as the quantity of sub-blocks increases. Here is the comparison between EfficeintNet-B0 and EfficeintNet-B7:
Deepfake Detection with EfficientNet: Experiments
A few experiments were held to assess practical performance of the EfficientNet architecture.
One of the researches involved a You Look Only Once solution abbreviated as YOLO-face detector and based on the EfficientNet architecture. It included a number of experiments. An evaluation metric Area Under the Receiver Operating Characteristic (AUROC) was used to appraise performance.
For instance, one of them saw EfficientNet and MTCNN solutions competing against each other. The former showed better results as it had fewer false positives. When applied to the CelebDF-FaceForencies++ data set, it demonstrated an 89.35% AUROC rate for pasting approach. MTCNN showed a worse performance: 83.39% AUROC rate for the same approach.
Another experiment from this research compared EfficientNet-B5 with the XceptionNet, which has a depthwise separable convolution. The competing neural networks were pre-trained with the ImageNet weights.
Such additional layers as Max pool 2D, ReLU activation function, dropout layer with a 0.2 probability were used during experiment. As a result, EfficientNet-B5 outperformed XceptionNet showing a higher AUROC rate: 8-10%.
Another research applied EfficientNet on such datasets as Stanford Cars, CIFAR100, FGVC Aircraft, and others.
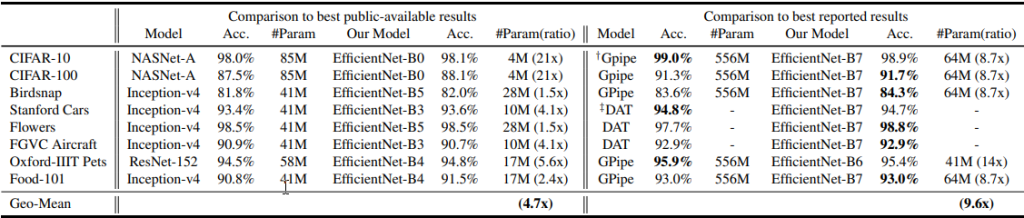
Results show that while EfficientNet is 8.4 times smaller, it provides an 84.3% accuracy with 66M parameters and 37 billion FLOPS. Among all else, EfficientNet-B3 beats ResNeXt-101 in turn of resource consumption as it requires much fewer FLOPS: 18x times.

Another test involved EfficientNet-B5, DeepFake Detection Challenge Dataset (DFDC), and also additive angular margin loss dubbed ArcFace. (Serving as an alternative to the softmax+cross-entropy loss).

While offering their own solution, which includes an ensemble of Gated Recurrent Unit (GRU), MTCNN and EfficientNet, authors also came to a conclusion that EfficientNet-B5 demonstrates highly accurate results on its own.
Competitions
In 2021 a competition dubbed 3D High-Fidelity Mask Face Presentation Attack Detection Challenge was hosted. Its purpose was to tackle the threat of 3D masks during the presentation attacks (PAs). The contest employed a special High-Fidelity Mask dataset (HiFiMask).
Various solutions were presented including EfficientNet. Their goal was to recognize masks that had different "skin tones", were made of various materials and presented in different lighting conditions.
As a result, an EfficientNet-based solution offered by VisionLabs showed the highest results: BPCER rate was 2.33% with 101FN samples.

Apart from other techniques, this solution employs Dual Shot Face Detector (DSFD), EfficientNet-B0 trained with binary cross-entropy loss, 6 descriptors of length 320 to guarantee better liveness detection, and other means.

The study shows that this EfficientNet-based solution demonstrates impressive results when detecting separate face regions: nose, ears, mouth. For eyes, APCER rate is 3.55% and BPCER is 2.54%. Overall, this method appears promising at tackling PAs featuring realistic 3D masks. Besides, EfficientNet successfully presented its potential during such deepfake detection competitions as Deeper Forensics Challenge 2020.
FAQ
What is EfficientNet?
EfficientNet is a cost-effective and highly accurate CNN architecture type.
EfficientNet is a Convolutional Neural Network architecture. Due to its unique method of compound coefficient, it provides proportionate scaling of all neural network dimensions: resolution, width, and depth. Its structure also involves such elements as inverted bottleneck residual blocks.
What sets EfficientNet apart is that it is more cost-effective (optimizing FLOPS) and accurate when compared to existing alternatives (AlexNet, SPPNet). According to statistics, EfficientNet shows an 84.3% accuracy when tested on the ImageNet.
This makes the EfficientNet architecture a favorable choice for facial liveness widely used in Know Your Client procedures.
EfficientNet & EfficientDet: Difference in Architecture
EfficientDet is an advanced modification of EfficientNet that employs Bi Feature Pyramid Network.
EfficientDet is basically a modification of the EfficientNet architecture. It proposes two novel techniques:
- BiFPN. Bi Feature Pyramid Network includes bottom-up feature fusion branch, skip connections from the initial feature map, removed one-input nodes, weighted average to make resolution feature maps to assist fusion at different capacity, etc.
- Compound scaling. It is used for scaling BiFPN, thus increasing the network’s efficiency. It enhances the backbone, box and class network, resolution, etc.
Theoretically, EfficientDet can overshadow EfficientNet in terms of facial liveness used in antispoofing and other technologies.
Which ANNs are Best Suited for Deepfake Detection?
Convolutional Neural Networks are among the best solutions for deepfake detection. Numerous studies and competitions revealed a number of neural networks that provide accurate deepfake detection. EfficientNet — a Convolutional Neural Network architecture — has appeared as one of the best solutions for deepfake detection. It consists of 8 models and is based on the compound coefficient principal.
EfficientDet is a modification of EfficientNet. It’s based on Bi Feature Pyramid Network and compound scaling. Other prominent solutions include such CNNs as DenseNet, ResNet and ResNetV2, VGG16 and VGGFace, and others used for antispoofing purposes.
Which Neural Networks are Most Often Used for Face Recognition?
Convolutional Neural Networks are seen as the most effective and popular anti-deepfake tool so far.
Convolutional Neural Networks are considered to be the best face recognition tool — they show an outstanding performance with images, videos, as well as human speech.
EfficientNet and its modified version EfficientDet show particularly impressive results. The former is known for its compound coefficient element, which makes it possible to enhance performance of the network’s dimensions evenly. The latter takes an extra step by bringing in the BiFPN component. Other proposed solutions are ResNet, VGGFace, FisherFaces, DeepID Test, etc. CNNs are used as part of remote KYC, AML and other antispoofing techniques.
To read on about deepfake detection competitions which show the cutting-edge technologies in antispoofing, click here.
References
- Alex Waibel on Carnegie Mellon University's site
- Alex Weibel on Wikipedia
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- A Comprehensible Explanation of the Dimensions in CNNs
- EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling
- Complete Architectural Details of all EfficientNet Models
- FLOPS (Wikipedia)
- InceptionV2 on paperswithcode.com
- How do bottleneck architectures work in neural networks?
- Deepfake video detection: YOLO-Face convolution recurrent approach
- Measuring Performance: AUC (AUROC)
- CIFAR100
- FGVC Aircraft
- Deepfakes Detection with Automatic Face Weighting
- Deepfake image examples used for testing ANNs
- DeepFake Detection Challenge Dataset
- 3D High-Fidelity Mask Face Presentation Attack Detection Challenge
- Review of Face Presentation Attack Detection Competitions
- Dual Shot Face Detector
- 3D mask presentation attack detection via high resolution face parts
 Antispoofing
Antispoofing


