
Digital face manipulation has recently emerged as a significant threat to biometric systems. Although manipulation of images/photographs — photoshopping — has been a popular practice for many years, video manipulation has been relatively unknown. Video manipulation became possible after the introduction of the video deepfakes. The deepfake technology has been in development since 1990s with Video Rewrite being the first tool of its kind. This program could alter the lip movement of a person in a video, so it would realistically match a completely different audio track. But it was not until 2017 when facial deepfakes became a global phenomenon. Using tools like MelNet, Wombo, Adobe Voco or Face Swap Live, even amateur users can produce believable face and voice manipulations.

Experts predict that fabricated materials using digital face manipulation — including cheapfakes — can be used for disinformation, fraud, reputational damage, and even terrorism. With the rise of manufactured and manipulated content online, even real content may be discredited; many viewers may experience reality apathy (a state where it is too overwhelming to discern what is real and what is fake) or the liar’s dividend (where someone may deceive the public by claiming a real piece of content is fake.)
In one instance, deepfake allegations were used as a pretext for a failed coup d’etat in Gabon. A video in question capturing the president giving a speech and appearing in a state of ill health – what some viewers described as a “post-stroke appearance.” The video was used by the country’s military to spawn rumors and hysteria among the people. Though it was never determined for certain if the video was a deepfake, it exposed the public to the unsettling possibility of even slight alterations being used to incite political chaos.

Digital Face Manipulation
As observed by Antispoofing.org, Digital face manipulation is a technique, which allows altering biometric/anatomical properties of the face or creating a new face from scratch using specialized digital tools. These tools can vary from mainstream applications like FaceApp or MyHeritage to sophisticated neural networks.
Types of Face Manipulation
Currently, there exist 6 principal types of face manipulation.
Entire Face Synthesis

Face synthesis technology is capable of modeling a fake and nonexistent face from scratch. This method puts to work two “competing” neural networks and by working in tandem, they form a Generative Adversarial Network — GAN. The first network is called Generator G: it is responsible for distributing and creating new visual samples. Its counterpart is called Discriminator D and its purpose is to assess whether the visual sample comes from the genuine training data and is not fake. As a result, such a GAN can produce highly believable results. A GAN may use databases with up to 10K Faces, as its primary source of samples.
Identity Swap
This technique involves replacing a person’s original face (source) with the face of a different person (target). Face swapping can be done using tools such as DeepFaceLab, Face Swap Live or ZAO — most of which are freely available and do not require any programming skills. These apps achieve a face swap through a complex algorithm. It includes face detection/cropping, extraction, new face synthesis and the final blending. The last stage subtly mixes the “extracted” face with the source video.
Morphed Face
This method merges two (sometimes more) different faces into a morph, a new face that retains biometric characteristics of both at the same time. Since the morph resembles both people, it can potentially be successful at passing verification as one or more individuals. If a fraudster manages to obtain an authentic ID document with a morphed photo inside, individuals can share it, for example, to cross the border illegally.
Face morphing typically includes three stages:
- Landmark identification. It determines the key points of faces (eyes, lips, nose, etc.) and their location and shape.
- Warping. It creates geometric alignment of the facial features and the overall face shape. The landmarks are positioned to the average of the corresponding key points in the source portraits.
- Color blending. The color values of the multiple images in use are carefully blended together.
.png)
The challenge with morphs is that they are difficult to detect with the naked eye as well as computer algorithms. As a result, face morphing poses a serious threat to facial recognition systems: from their efficacy to public reputation.
Attribute Manipulation
This technique is also called “face retouching,” as it involves manipulation of facial attributes. Attribute manipulation is capable of altering a certain facial element: hair, eye color, skin texture, and so on. FaceApp is the most commonly known attribute manipulation tool. This method also employs GAN, particularly the Invertible Conditional GAN (IcGAN). In this case, an encoder works in unison with a conditional GAN, providing a high-level attribute manipulation.

Expression Swap
Expression swap, also known as face reenactment, basically “puts” one person’s facial expression on the face of another person. Emotions such as smiling, frowning, smirking, etc. can be manipulated and tweaked with the help of expression swap. This method employs various tools including GANs, Neural Textures and Face2Face. In essence, they all perform the same function: extracting the source expression and transferring it to the target footage, while also retaining the target’s identity.
Another technique of expression swap uses Neural Textures which utilize the original video data to learn a neural texture of the target subject.

Audio-to-Video & Text-to-Video
Audio-to-video and text-to-video methods are based on the same principles as the first known deepfake tool Video Rewrite. Converting audio and text data to speech is possible when a recurrent neural network equipped with Long Short-Term Memory (LSTM) is employed. Basically it analyzes the audio wave to learn which vowels/consonants are uttered by the speaker. It then provides an accurate mapping of the mouth shapes, as well as correct lip movement tempo. Moreover, a conditional recurrent generation network is capable of producing realistic facial expressions and head movement.
Examples







Mitigating Digital Face Manipulations
Digital face manipulation can be detected and mitigated using techniques proposed by experts and researchers. However, no technique has yet been able to provide a 100% failproof detection results.
Detection Using Multiple Data Modalities
Multiple data modalities refer to:
- Audio spectrogram analysis
In this deepfake detection method, Convolutional Neural Network models (CNN models), Recurrent Neural Networks (RNNs), Gated Recurrent Units (GRR) and Long Short-Term Memory networks (LSTMs) are used as the primary analysis tools. They are used for extracting features from a video or a static image and detecting artifacts typically “left” by a deepfake tool.
- Video spatio-temporal features
This method employs a CNN to analyze audio data in order to differentiate between synthesized and genuine audios. The method is based on Fast Fourier Transform (FFT) and Discrete Fourier Transform (DFT). They are used for retrieving Fourier coefficients, converting them to decibels and then constructing a sound spectrogram. Deepfake audios are then detected using the intensity (“thickness”) of audio signal and its correlation with the frequency and time data. Successfully detecting deepfake audios can also serve as extra evidence in exposing a deepfake video.
- Audio-video inconsistency analysis
This method matches video and audio analysis and can increase chances for successful deepfake detection. Inconsistency analysis is based on detecting dissimilarities between phonemes, which are sound units that distinguish words and visemes. Visemes are lip movements accompanying phonemes. By analyzing potential mismatches between them, this method can successfully detect a deepfake and discard it.
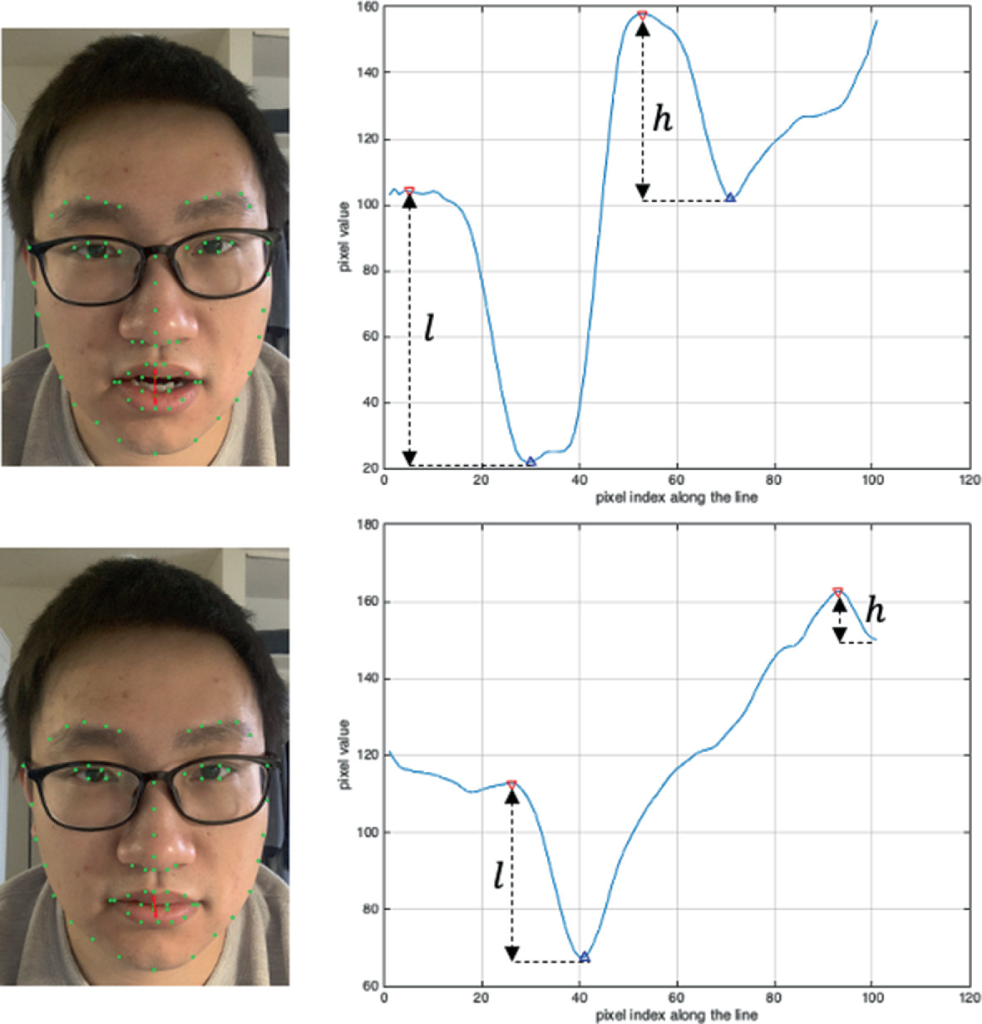
Algorithms Based on Heart Rate Estimation
Estimating the heart rate of the speaker in a video can lead to deepfake detection. DeepFakesON-Phys is a detector that analyzes the heart rate of a speaker and uses the information to differentiate between a real speaker and a manipulated footage or a completely synthesized persona. This detector gathers data invisible to a naked eye such as oxygen concentration and illumination levels etc. Changing oxygen levels can have a direct impact on the appearance of a human such as changing face/skin colors. Additionally, temporal integration of frame-level scores are used to ensure more accurate results.
Face Morphing Attack Detection Methods

Morphing Attack Detection or MAD utilizes feature extraction method with the help of three descriptor types:
- Texture descriptors. They will find changes left by the morphing process, such as artifacts in the eye region, etc.
- Gradient-based descriptors. They take into consideration histogram calculations and properties of the feature vectors.
- Descriptors learned by a deep neural network. They extract features from the footage for further analysis.
This method can use unaltered photos — passport or ID images — for reference.
As for identity document verification, another method which is proved to be effective at state borders is using special forensic devices. These devices feature a sliding light with a very sharp angle, allowing frontline officers to detect all sorts of overprints in no time.

References
- Video Rewrite, Origins of Deepfakes
- MelNet. A Generative Model for Audio in the Frequency Domain
- Top AI researchers race to detect ‘deepfake’ videos: ‘We are outgunned’
- Video featuring president Ali Bongo caused a turmoil in Gabon
- How to Produce a DeepFake Video in 5 Minutes
- 10k US Adult Faces Database
- Nasolabial folds
- Example of morphing detection
- Facial Morphing: Why It Can Threaten National Security & How to Protect Against It
- Viseme detection in progress
- Expression swap is often used for animating historic paintings and sculptures
- Fake It Till You Make It. Face analysis in the wild using synthetic data alone
- Fake faces generated by thispersondoesnotexist.com
- Identity swap is popular among social media users
- Example of morphing two faces
- Attribute manipulation is simple to achieve
- Expression swap used to animate a painting
- Audio-to-video used for animating static images
- What is a phoneme?
- Visemes
- DeepFakes Detection Based on Heart Rate Estimation: Single- and Multi-frame
 Antispoofing
Antispoofing



{kind=link}