
Deepfake Datasets: Origin & Practical Usage
Deepfake dataset is a collection of artificially synthesized media, which can include photo, video, and audio materials designed in accordance with the deepfake standardization. Their origin was urged by the proliferation of deepfake media that represents a steadily growing social threat.

Deepfakes have become a widespread phenomenon in 2017, so the datasets dedicated to the issue began appearing recently: circa 2018. One of the first such datasets was DeepfakeTIMIT based on the VidTIMIT database originally created in 2008. It contains audiovisual samples doctored with face swapping based on Generative Adversarial Network (GAN) methods.
A tremendous step further was made after FaceForensics and its expanded version FaceForensics++ have debuted. At the moment, it contains 1,000 facial deepfakes — videos digitally manipulated with such tools as Face2Face and others.
Datasets for deepfake detection received a new impetus after challenges in that area were introduced. One of them, Deepfake Detection Challenge (DFDC), offered participants an enormous database consisting of 128,154 consented videos. (Featuring hired actors).
These datasets serve an important goal. As DFDC showed, deepfake detection methods demonstrate a worse performance when presented with previously unseen falsified data that was created with undisclosed and probably novel techniques.
Generations of Datasets
Researchers note that different datasets belong to their respective generations. All in all, it’s possible to highlight 3 primary Generations:
- First Generation. It includes the simplest datasets that contain 1,000 or less sample videos with just 1 million frames. Moreover, the videos featured do not legally belong to the database as they were harvested from YouTube and later altered. Examples: UADFV, DF-TIMIT, FaceForensics++.
- Second Generation. It offers from 1,000 to 10,000 videos presented with 1-10 million frames. Usually, this data is of higher quality and videos available for use are officially consented. However, such a collection may not offer enough identities for comprehensive detection algorithm training. Examples: Celeb-DF, Google-DFD.
- Third Generation. The last Generation can offer up to 100,000 videos and more with unique identities and deepfake techniques applied to each sample. Besides, they feature paid actors who pose in different surroundings, which adds up to the challenge even more. Examples: DFDC dataset.
Interestingly, the Third Generation datasets do not disclose methods and techniques used for deepfake production. Obviously, this measure serves to increase the challenge difficulty and help design highly accurate and failproof solutions.
The Main Datasets Used for Deepfake Detection
The database Generations listed above sparked a number of datasets actively used today. Some, like FaceForensics++ are publicly available and welcome any researcher to try their methods. Others were exclusively introduced as part of the competitions and may be inaccessible.
UADFV
The UADFV was developed at the University of Albany. Its primary purpose is to assist in deepfake detection through the physiological signals. (Sometimes referred to as "liveness indicators".)
Typically, these signals include facial expressions, lip movements, and so on. However, UADFV mainly focuses on blinking, as it’s not presented and analyzed in detail, according to the authors.

The dataset contains 98 samples: 49 real videos harvested from YouTube and 49 fake videos processed with FakeApp. Each length of each video is 11 seconds averagely, while resolution is 294x500 pixels.
DF-TIMIT
Deepfake-TIMIT uses an older dataset VidTIMIT as its fundament. It includes 640 videos based on the original 10 image sequences of 32 people. The videos were created with a face swapping technique, which involves GAN algorithms. To make it more challenging, authors selected image pairs that featured people with similar appearances.

The dataset is divided into 2 groups. Group 1 contains 320 low-quality videos with the 64x64 resolution and 200 frames. Group 2 contains 320 high-quality videos with the 120x120 resolution and 400 frames.
FaceForensics++
The original Faceforensics dataset was designed for media forensics and contains half a million deepfake images harvested from 1,004 videos. They feature ground-truth masks and their main goal is to help to solve segmentation and classification challenges effectively.
FaceForensics++ features 1,000 videos manually selected from YouTube with a male to female ratio being 60% - 40%. The digital face manipulation techniques employed are Deepfakes, NeuralTextures, FaceSwap and Face2Face.
Video quality varies:
- 55% of the data is low quality (854x480 VGA resolution)
- 32, 5% is HD (1,280x720 HD resolution)
- 12, 5% is full-HD (1,920x1,080 full-HD resolution)
The output provided by the FaceForencics++ model includes manipulated videos and ground-truth masks.
Google/Jigsaw DeepFake Detection Dataset
The Google/Jigsaw is an open-source project curated and sponsored by Google. It is integrated into the FaceForencics benchmark, which features a repertoire of methods including NoSenseAtAll, StableForensics, Firefly, and others.
The dataset contains "hundreds of videos" that will be updated to meet the growing challenges of the deepfake technology, as announced by Google. All videos are fully consented and free-to-use for the researchers.

Facebook DeepFake Detection Challenge Dataset (DFDC)
DFDC has a colossal dataset with 128,154 consented videos. They are separated into 4 categories:
- Training set.
- Public Validation set.
- Public Test set.
- Private Test set.

Videos were recorded both indoors and outdoors to provide a variety of environments. Besides, two face-swapping methods were used:
- Method A. High-quality face-swap images with an even proportion of the source and facial manipulations.
- Method B. Low-quality face-swaps.
Video resolution varies from sample to sample with an average 15 seconds length.
Celeb-DF
Celeb-DF is an extensive project that offers 5,639 videos with more than 2 million frames. It features 59 celebrity personas, with the source videos borrowed from YouTube, which have undergone an advanced synthesis process.

The frame size is 256x256, while an average video lasts for 13 seconds. Frame-rate is 30 FPS and the scenery presented has varying characteristics: different lighting, backgrounds, face sizes, and so on. The dataset also provides diversity in terms of ethnicity, age, and gender.
DeeperForensics 1.0
DF 1.0 offers 60,000 videos. The resolution is 1,920x1,080. An automatic face-swapping technique is applied to 17:6 million frames. All videos are fully consented: they feature 100 actors from 26 countries, thus garnering skin tone, age and gender variety.
They were instructed to perform 8 emotions: disgust, fear, joy, anger, disdain, surprise, sadness, and neutral expression at different angles: from -90° to +90°. Additionally, they mimicked 53 expressions from the 3DMM blendshapes.
WildDeepfake
The goal of the WD dataset is to provide training data that was created in the "field conditions": nature, different room types, with different lighting, facial expressions, poses, etc. It contains 7, 314 face sequences harvested from the internet.

DF-Mobio
Developed at Idiap Research Institute, DF-Mobio contains 15,000 fake videos and 30,000 real videos. Deepfakes, processed with a GAN, feature 72 identity pairs who share resembling appearances: eyes, hair, facial features, and so on. The dataset simulates such scenario as video calls.

Dataset Comparison
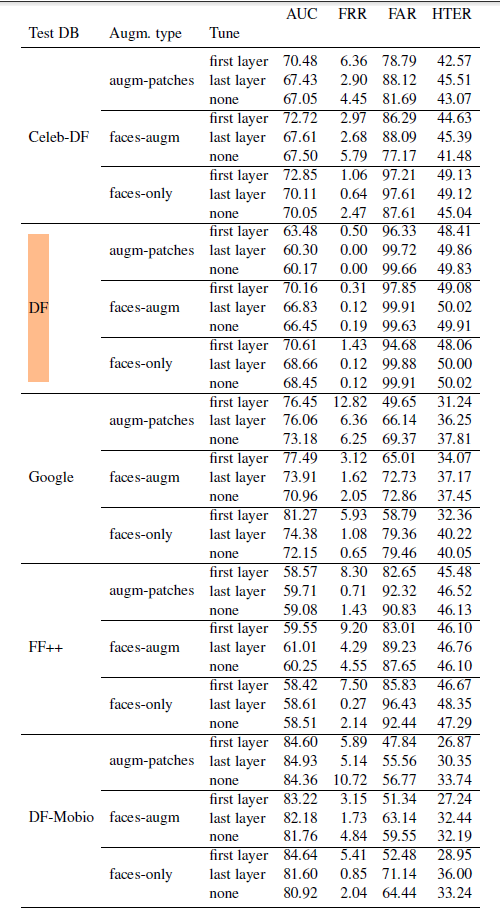
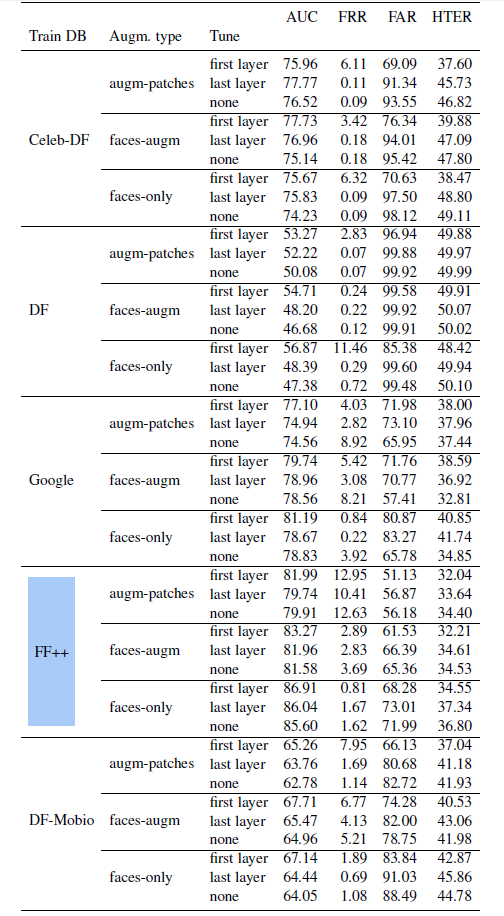
Empirical data shows that FaceForensics++ and DF-Mobio show the best results as they lead to the lowest error rates. The report suggests that these datasets could be used in tandem for testing/training. However, "data and training fusion" require a separate sturdy.
FAQ
What are the main datasets used for deepfake detection?
Deepfake datasets allow training and testing deepfake detection methods.
There are at least three main deepfake datasets: Facebook’s DFDC, FaceForensics++ and Celeb-DF. Their primary advantage is accessibility to a large assortment of consented or publicly available videos and accessibility.
Additionally, these datasets offer a variety of ethnicities and genders, video backgrounds, digital face manipulation techniques applied to them, and so on. They are widely used for training and testing modern antispoofing recognition systems for accuracy and reliability. Other prominent actively used datasets include Google/Jigsaw DeepFake Detection Dataset, WildDeepfake, DF-Mobio, DF-TIMIT, and DeeperForensics 1.0.
What are the best datasets for deepfake detection?
Experts name DFDC, FaceForensics++ among the best deepfake detection datasets.
Almost every deepfake detection dataset has its own benefits. The DFDC dataset is one of the best options as it offers an extensive sample collection. All videos in its data corpus are consented featuring paid actors. Moreover, undisclosed deepfake techniques have been applied to the videos, thereby increasing the challenge for the testing.
FaceForensics++ is another dataset praised for its accessibility and video samples of varying quality: from low-resolution to high-definition. WildDeepfake dataset contains data captured in the real-life ambiance. DF-Mobio dataset mimics typical scenarios like video calls while Celeb-DF is one of the most commonly used datasets in the research community.
How many samples do modern datasets for deepfake detection consist of?
Deepfake datasets vary in size, as well as in sample diversity and quality.
Perhaps the largest deepfake dataset at the moment is DeeperForensics 1.0 with 60,000 high-quality videos, 100 paid actors and 17.6 million frames. However, this dataset has received criticism for insufficient number of deepfake methods applied to produce the videos. (Which can hinder AI face recognition training).
The DFDC dataset used for challenging the best antispoofing techniques is the second-largest dataset with 5,214 videos and 66 paid actors. An essential benefit of this dataset is that it offers a number of “secret” techniques that the samples were altered with. FaceForensics++ dataset is the third largest with 3,431 videos.
To read more about how deepfakes are used in spoofing, read our article on facial deepfakes.
References
- ‘Deepfakes’ ranked as most serious AI crime threat
- 69 Funniest Face Swaps From The Most Terrifying Snapchat Update Ever
- VidTIMIT Audio-Video Dataset
- FaceForensics++: Learning to Detect Manipulated Facial Images
- Deepfake Detection Challenge. Identify videos with facial or voice manipulations
- Improving Generalization of Deepfake Detection with Data Farming and Few-Shot Learning
- The DeepFake Detection Challenge Dataset
- Deep Learning for Deepfakes Creation and Detection: A Survey
- Real (above) and manipulated (below) samples from UADFV
- DF-TIMIT dataset sample
- FaceForensics++: Learning to Detect Manipulated Facial Images
- Results for NoSenseAtAll
- Results for StableForensics
- Results for Firefly
- Contributing Data to Deepfake Detection Research
- DFDC (Deepfake Detection Challenge)
- Celeb-DF dataset sample
- WildDeepfake versus 5 existing datasets
 Antispoofing
Antispoofing



