
Face Antispoofing Databases: Types, Role & Application Areas
A face antispoofing database represents a collection of facial images used for training and testing existing detection solutions. These datasets range in sample variety, visual quality, digital face manipulation methods applied to them, types of Presentation Attacks (PAs) featured, environments, modality and sensors, etc. They help improve facial anti-spoofing, with its typical types, countermeasures and challenges. The earliest databases of this kind can be traced back to 1993 when the FERET database was released by NIST together with the Army Research Laboratory. The database was created to make facial recognition algorithms suitable for commercial usage.
The emergence of deepfakes and their growing concern emphasized the need for diverse datasets to train antispoofing detection methods. Therefore, around 2018, more datasets were introduced that offer a bigger selection of samples, individuals, scenery, and manipulation techniques. One of the largest collections is the DFDC dataset, which accompanied the eponymous challenge: it contains 128,154 videos with paid actors.

Today’s databases extend beyond mere face detection. They feature various modalities, such as Near Infrared (NIR) and Shortwave Infrared (SWIR) sensors, novel attack types, controlled and open field environments, indoor and outdoor scenery, different lighting levels, and other nuances that help train a more accurate facial recognition/antispoofing system base don either passive or active liveness detection.
Datasets for Face Antispoofing
Since the early 1990s a number of face recognition (FR) databases have been developed. The following examples can be highlighted:
FERET
The first FR database in history, Face Recognition Technology (FERET) was conceived in December 1993. Over the course of three years, 14,126 images of 1,199 individuals were collected with 365 duplicates taken on different days. In 2003, the images were upgraded to 24-bit HD quality. Despite its age, the database is still available on demand.

FRGC
Face Recognition Grand Challenge (FRGC) organized by NIST, began in 2002 and lasted for one academic year. With the goal "to promote and advance face recognition technology" for the US government, it also introduced a database of the same name. It includes 50,000 samples collected at the University of Notre Dame during the subject sessions. In other words, images of a person were captured at the same time when their biometric data was obtained.
The sample selection includes 4 controlled studio-quality still images, 2 uncontrolled still images, and 1 three-dimensional image. They contain a limited variety in terms of ethnicity and lighting, as well as balanced gender diversification. Minolta Vivid sensor was used for 3D images, while Canon PowerShot G2 was used for taking still images.
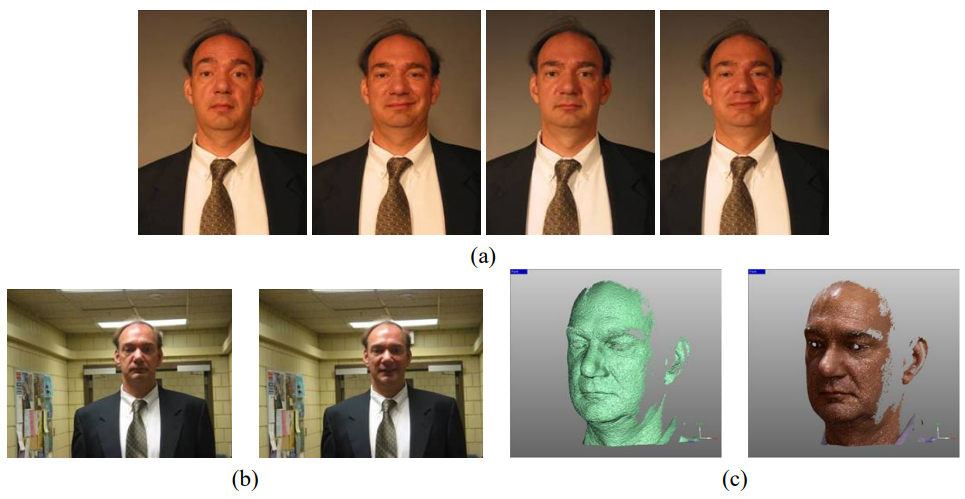
CelebA-Spoof
CelebA-Spoof is an extensive non-commercial dataset, which contains 625,537 photos borrowed from 10,177 individuals. The sample material features 43 rich attributes separated in 4 categories: Spoof Type, Illumination Condition, and Environment.

The CelebA-Spoof database includes a variety of illumination, types of fake imagery, scenery, and other samples proper for training a robust face liveness detection system. To make it more effective, a mixture of facial contours, hair, complexion, skin tones, expressions, and other accessories is also provided.

MorphDB
MorphDB is a database developed for face anti spoofing with a focus on facial morphs, specifically those used in paper documents. It offers 100 morph images produced with the Sqirlz Morph 2.1 application with the morphing factor in the [0.3;0.4] range. Images are presented as both digital and printed copies that were later re-scanned. Like many other morph datasets, MorphDB seems to be publicly unavailable.
AMSL
AMSL is a publicly accessible morph dataset based on the Face Research Lab London Set. It consists of 2,175 facial morphs that are in compliance with the ICAO portrait quality guidelines and can be stored on an electronic Machine-Readable Travel Document (eMRTD) chip. (As face morphs are mostly used for spoofing border control systems).

ROSE-Youtu Face Liveness Detection Dataset

The ROSE-Youtu Face Liveness Detection Dataset is a comprehensive collection designed for face anti-spoofing research, addressing a broad spectrum of illumination conditions, camera models, and attack types. Here are the main characteristics of the dataset:
- Composition: The dataset comprises 4225 videos featuring 25 subjects in total, with 3350 videos and 20 subjects available publicly. The total size of the publicly available portion is 5.45GB, with an additional 1.25GB of pre-processed data for a specific protocol.
- Data Collection: Videos were recorded using five different mobile devices: Hasee smartphone, Huawei smartphone, iPad 4, iPhone 5s, and ZTE smartphone, ensuring a variety of resolutions and qualities. Each subject has 150-200 video clips, each lasting around 10 seconds, captured with a front-facing camera at a distance of 30-50 cm.
- Variety of Conditions: The dataset covers five different illumination conditions in an office environment, and if a subject wears eyeglasses, additional videos are included.
- Spoofing Attack Types: It includes three main types of spoofing attacks: printed paper, video replay, and masking attacks, each with specific variations to challenge liveness detection algorithms.
- Evaluation Protocols: The dataset is divided into training and testing subsets for intra-dataset evaluation, with videos from the first 10 indexed subjects used for training. A new Client-Specific One-Class Domain Adaptation Protocol is also introduced for a more specialized evaluation.
- Usage and Conditions: The dataset is intended for academic research and is available for free to researchers from educational or research institutes for non-commercial purposes. Users must agree to a release agreement that restricts redistribution, derivative creation, or commercial use of the dataset.
- Naming Convention: Videos are named following a specific template that includes information on the type of video, whether the subject is speaking, the device used for recording, whether the subject is wearing glasses, and the person ID.
This dataset provides a rich resource for developing and testing face liveness detection algorithms, with a particular focus on combating spoofing attacks in various real-world conditions.
iBeta Level 2 Dataset, 33 000 attacks
-9-1.png?generation=1687976769447161&alt=media)
The iBeta Level 2 Dataset dataset consists of six diffrent types of videos: real face videos, 2D mask attacks with and without eyes cutting, 3D cardboard attacks, attacks with latex and silicon masks.
Real Face Databases
A number of databases have a specific purpose of delivering ‘real-life’ images that were not staged in a controlled environment like a professional studio. A significant advantage of such material would be its numerous imperfections such as insufficient lighting, unpredictable angles, blurring, lower image definition, random expressions, and so on.
Among them researchers highlight:
Labelled Faces in the Wild
Labelled faces in the Wild was conceived at the University of Massachusetts and features data corpus obtained from the videos and images available online. The database includes highly imperfect images captured in various environments. It impacts quality, illumination, and other parameters. There are 13,233 images in total, featuring 5,749 people. However, the labelling accuracy of the used images is only 77%, which makes training and evaluating somewhat challenging.

The BioID Face Database
The BioID dataset incorporates 1,521 gray level images with a 384 x 286 pixel resolution. The dataset mostly focuses on face detection rather than recognition or antispoofing. It features an assortment of images photographed in office or home environments, with different poses, expressions, and illumination levels, which makes it a suitable option for training a passive liveness solution.
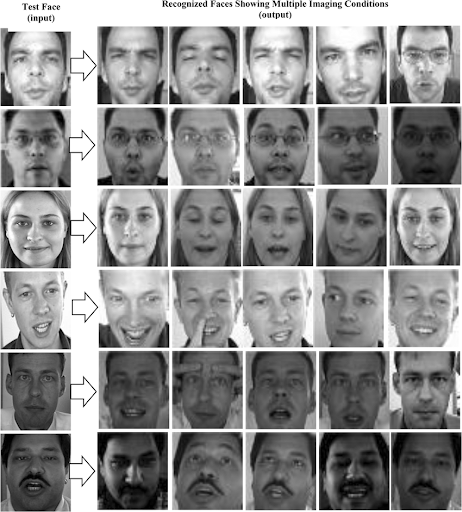
Caltech 10000 Web Faces
Caltech 10,000 Web Faces provides a repertoire of samples captured in real-life conditions. The database provides a mixture of poses, ages, illumination and facial expressions. It provides added diversity in the form of varied background details. However, it does not give specific identities of the people presented, which can hinder facial recognition training.

Landmarked Databases
Landmarked databases pinpoint coordinates of the facial features — eyes, nose tip, lips — which is necessary for certain software applications.
MUCT

Milborrow University of Cape Town (MUCT) dataset contains faces of 755 volunteers with 76 landmarks manually highlighted. The database provides ethnic, age and gender diversity with random expressions, facial occlusions, poses, and so on. The images included are captured with five cameras simultaneously and present an image quality of 640 x 480 pixels.

AR
Created at Purdue University, it contains 508 color images (768 x 576 resolution), featuring 126 individuals. Additionally, 22 landmarks are pinpointed in the featured samples with a variety of emotional expressions such as neutral, mild anger, and smile.
IMM
The IMM dataset from the Technical University of Denmark features 240 images (640 x 480 resolution) of 40 people. 58 landmarks are highlighted with six different poses and varying light conditions.

PUT
Compiled at the Poznan University of Technology, the PUT dataset contains 2,193 color photos (2048 x 1536 resolution) of 200 individuals with 199 landmarks highlighted.
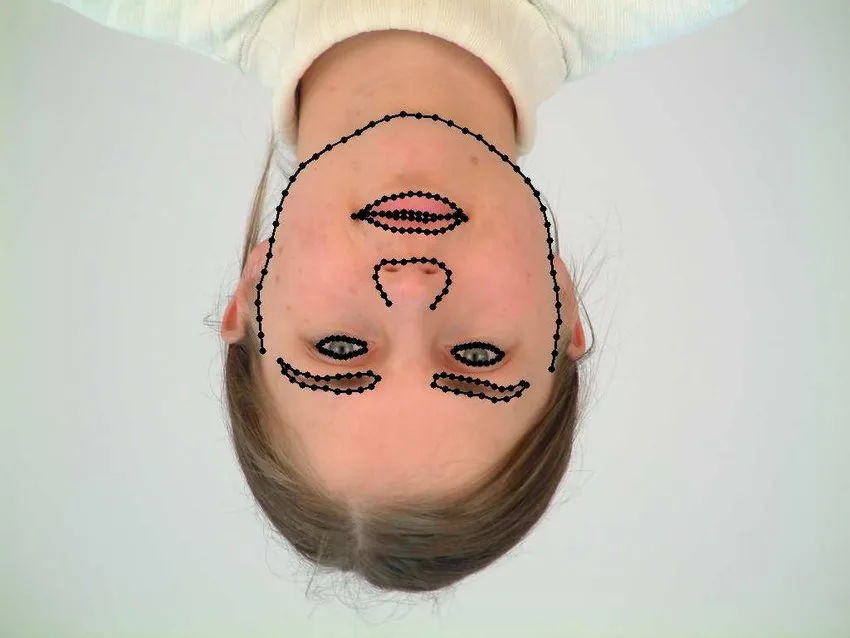
XM2VTS database
The XM2VTS database is a freely available dataset, which offers a landmark subset. The subset features 2,360 color photos (720 x 576 resolution) of 295 people with 68 landmarks highlighted. It is noted that this dataset is quite effective for training Active Shape Models (ASMs), as it offers a rich assortment of faces and facial landmarks.

Animation Faces
AnimeCeleb is a large-scale database comprising of animated images. It was created from 3,613 3D cartoon models with full-body information — such as skeletal bones — borrowed from DeviantArt and Niconi Solid.

AnimeCeleb uses the obtained animations and turns them into 2D drawings with the open-source Blender software, with such aspects as Camera alignment, Light condition, and Image resolution. The dataset focuses on researching facial morphs, as well as on manipulating poses, head rotations, colorization, image harmonization, and other animation aspects.

Face Standardization
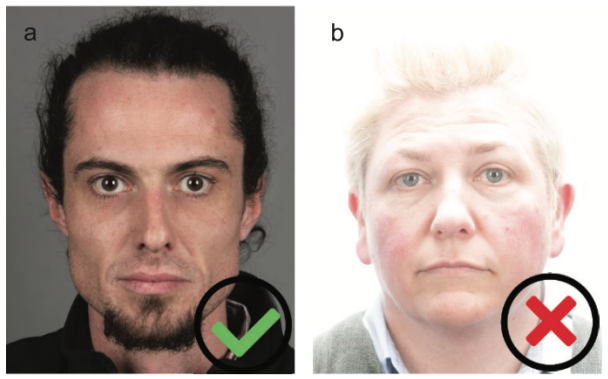
In order to regulate the quality of databases created, certain standards are used. Specifically, ISO/IEC 19794-5:2011 and ISO/IEC 39794-5:2019, which refer to data and biometric data interchange. These standards specify parameters such as Unified quality score FaceQnet, Capture-related quality elements and Subject-related quality elements etc.
FAQ
What are the main databases for face anti-spoofing?
Face anti-spoofing includes a number of notable databases used for training and testing.
To ensure accurate liveness detection and anti-spoofing in face recognition systems, a cavalcade of datasets has been introduced. The first dataset FERET mostly focused on recognizing faces. The subsequent database generations were primarily dedicated to facial liveness signals and potential attack scenarios.
Among them are DFDC dataset, Face Recognition Grand Challenge (FRGC) by NIST, CelebA-Spoof, AMSL, The BioID dataset, and so on. Some databases focus on a certain type of threat such as MorphDB. Others are dedicated to liveness detection in real-life conditions: Labelled faces in the Wild, Caltech 10,000 Web Faces, etc.
Are there any face anti-spoofing databases?
A cornucopia of facial anti-spoofing databases has been designed.
To deliver failproof liveness detection, facial recognition is trained with various datasets. Some are general-purpose implying that they focus on deepfake detection en masse. Other datasets consider more specific details: facial feature coordinates, image imperfections, various environments, morphed faces, and so forth.
The popular datasets include Face Recognition Grand Challenge (FRGC), CelebA-Spoof, CASIA-MFSD, Deepfake Detection Challenge, Labelled faces in the Wild, and many others. FERET database is also worth mentioning even though it’s not dedicated to anti-spoofing per se.
What is the first face anti-spoofing database?
The very first facial anti-spoofing datasets can be traced back to 2010.
The earliest facial anti-spoofing dataset appeared in 2010 as an addition to a study conducted by Tan et al., which focused on Lambertian reflectance model that could help differentiate 2D images and real three-dimensional human faces.
Prior to that, facial datasets chiefly focused on recognizing human faces — the very first example was the FERET database, which was conceived in 1993. However, a need for reliable liveness detection algorithms in face recognition had sprung up in the 2010s. This is largely attributed to the rise of mobile technology, which employs facial biometrics. (Even though the idea was first envisioned in 2005.)
How many photos do modern databases consist of?
Facial datasets can dramatically vary in size and quality.
Facial datasets commonly include thousands of samples. Those can be genuine photos, surveillance images, digitally manipulated footage, short videos, and even animation. The earliest facial dataset FERET (1993) had amassed 14,126 samples over 3 years.
Today, databases for recognition and liveness detection consist of large sample collections. The CelebA database comprises more than 200,000 images. Google Facial Expression Comparison offers 156,000 samples. UMDFaces includes 367,000 photos. YouTube with Facial Keypoints consists of 155,560 still frames and VGG Face2 has 3+ million images. Some authors suggest using an entire social media as a dataset, however it raises ethical issues.
Are there any databases of real faces?
Numerous facial datasets include a portion of genuine human faces.
Practically, most facial datasets include at least some portion of genuine facial images. The classic FERET database includes 14+ thousand photos of people who display various facial expressions and head poses. (The current version is 24-bit HD quality.)
Flickr-Faces-HQ (FFHQ) contains real human faces retrieved from Flickr with an original intention to train Generative Adversarial Networks (GANs). Real and Fake Face Detection intermingles authentic and synthetic images. Labelled Faces in the Wild (LFW) has been amassed with a Viola Jones facial detector to improve anti-spoofing in unconstrained conditions, etc.
Are there any databases of anime characters?
Some animation character datasets have been designed for facial recognition.
A number of facial datasets featuring animation characters has been designed for various purposes. A bright example is the large-scale AnimeCeleb dataset. It features 3,613 three-dimensional character models from cartoons, including classic anime. A lesser known database is Anime Face Dataset for generating new characters from scratch.
Some were created to make the search-by-pic feature more effective for animation enthusiasts as in the case of iQiyi. Others focus on correlation between a character’s facial expression and donation behavior of the users, facial morphing, and anti-spoofing to an extent.
Are there any standards for making databases of faces?
Two ISO standards exist to ensure quality of facial datasets.
Quality regulation for facial datasets has been introduced in two standards: ISO/IEC 19794-5:2011 and ISO/IEC 39794-5:2019. Together they focus on such parameters as:
- Subject-related quality elements.
- Capture-related quality elements.
- Unified quality score FaceQnet (JRC).
Among all else, ISO standardization pays attention to the scenery/scene constraints used in the dataset samples. Even though it’s intended as a helpful measure, the compliant images may turn out too pristine. While it’s beneficial at the early training phase, it won’t be effective for an anti-spoofing solution intended to work in unconstrained environments.
References
- DFDC (Deepfake Detection Challenge)
- NIR and SWIR Questions & Answers
- Color FERET dataset sample
- Color FERET Database
- Face Recognition Grand Challenge
- FRGC (Face Recognition Grand Challenge)
- Overview of the Face Recognition Grand Challenge
- CelebA-Spoof: Large-Scale Face Anti-Spoofing Dataset with Rich Annotations
- CelebA-Spoof
- Sqirlz Morph 2.1
- AMSL Face Morph Image Data Set
- Face Research Lab London Set
- Portrait Quality (Reference Facial Images for MRTD)
- Example of an MRTD
- Labelled faces in the Wild
- Labelled Faces in the Wild sample
- The BioID dataset
- Caltech 10,000 Web Faces
- Caltech database samples
- The MUCT Landmarked Face Database
- Milborrow University of Cape Town (MUCT) dataset
- IMM dataset sample
- The IMM Face Database - An Annotated Dataset of 240 Face Images
- Repositioned PUT dataset sample
- XM2VTS sample collage
- The XM2VTS database
- Active Shape Models by Wikipedia
- AnimeCeleb: Large-Scale Animation CelebFaces Dataset via Controllable 3D Synthetic Models
- Blender software
- ISO/IEC 19794-5:2011
- ISO/IEC 39794-5:2019
- Biometric Data Interchange Standards and ICAO 9303 Relevance
 Antispoofing
Antispoofing



